 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
对话澜码科技创始人周健:大模型的下一个开垦地,AI Agent!
作者:周雅
城头变幻大王旗,在大模型的领地,AI Agent几乎是当前最热的话题。
AI Agent火爆到什么程度?不久前“软件巨人”微软创始人比尔·盖茨在一篇名为《AI将彻底改变你使用计算机的方式》的博文中公开断言:
「未来5年内将进入AI Agent时代,它将改变人与计算机的交互方式,将颠覆软件行业,引领人类从“键入命令”到“点击图标”以来计算机领域最大的革命。」
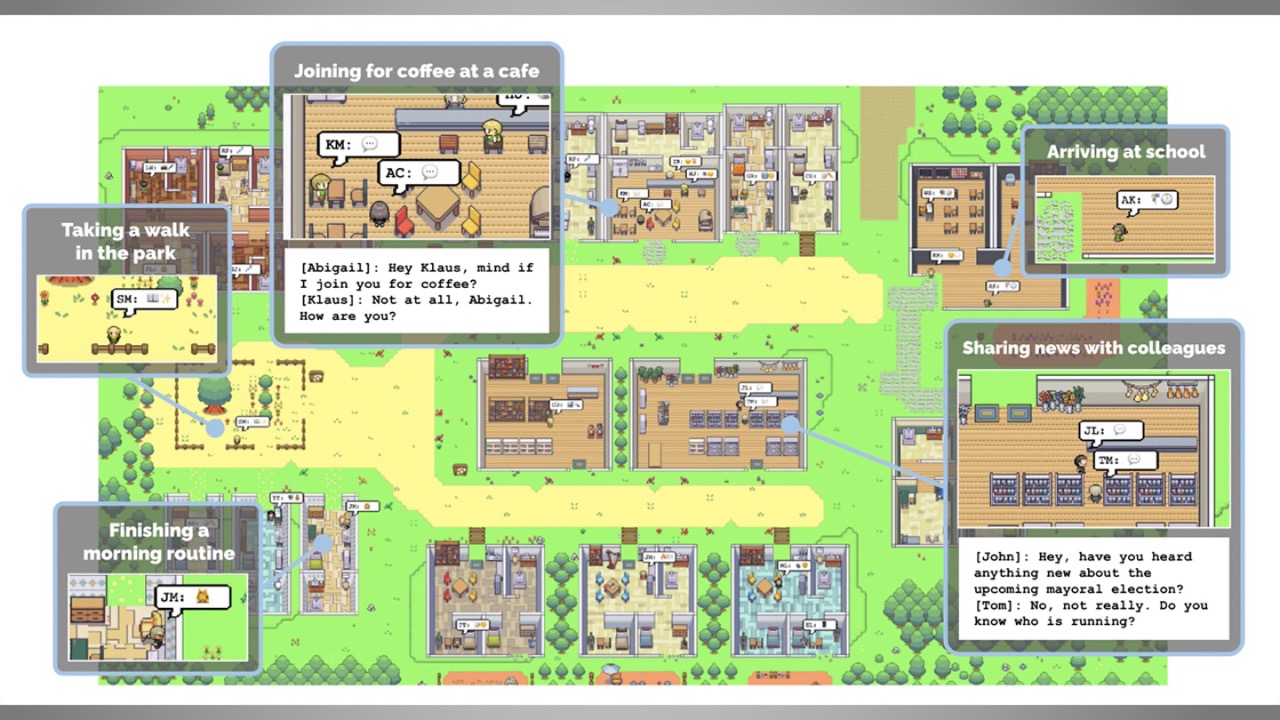
还有一项发人深省的“AI Agent”实验来自斯坦福和谷歌,该实验模拟了一个“西部世界”,在这个世界里,预装了25个AI Agent,每个智能体的行为方式与人类很像,比如起床后做早餐再去上班,艺术家作画,作家写作。他们参与对话并发表观点、建立浪漫关系、拥有长期记忆、还能规划未来。

图片来自斯坦福和谷歌论文《生成代理:人类行为的交互式模拟(Generative Agents: Interactive Simulacra of Human Behavior)》,根据斯坦福大学研究人员的说法,用户可以观察并干预代理计划他们的日程、分享新闻、建立关系和协调小组活动。
但什么是AI Agent(人工智能体)?
顾名思义,它是一种智能的实体。普通人会理解为《钢铁侠》中的Jarvis,而Open AI应用研究主管翁丽莲(Lilian Weng)在个人博客中下了一个定义:
“AI Agent = LLM(大语言模型)+记忆(Memory)+任务规划(Planning)+工具使用(Tool Use)”。有了后三者的能力,大模型就不再只是一个聊天机器人,而是能在更多广阔的场景中发挥价值。
随着“大模型落地难”的声音甚嚣尘上,AI Agent似乎成为玩家们的一道曙光——业界将其称之为“大模型的下半场”。
一时间,无论是不差钱的科技大厂,还是敢于冒险的创业公司,大家火速开启AI Agent征战模式。比如OpenAI的“GPT Store”,字节跳动旗下的“飞书智能伙伴”,昆仑万维的“天工SkyAgents”,智谱AI的CogAgent模型等。而澜码科技就是其中最早加入AI Agent浪潮的“玩家”之一。
澜码科技于2023年2月在上海成立,致力于“让人人都能够设计自己的智能体”。为什么选择做AI Agent?澜码科技创始人兼CEO周健的解释是:传统的系统是人适应机器,造成人成为数据的搬运工;今天有了大模型,我们有机会让机器去适应人,在这方面AI Agent前景广阔。
周健强调:“2023年是大语言模型的元年,2024年将是AI Agent的爆发年,AI Agent是大模型优先落地的最佳形态。”
不过我们虽然说澜码科技是新入局者,但周健对于AI Agent这一观察,最早可追溯到他在创办澜码之前的两段从业经历,这也是直接促成了他创业浓墨重彩的两笔。
第一段经历是在AI 1.0时代,周健加入依图科技成为第10号员工,在那里,他经历了CV(计算机视觉)技术从不成熟到成熟的完整阶段。
在依图时期,周健坦言自己深刻了解了AI应该如何落地:从技术侧,算法怎么做;从应用侧,产品怎么能端到端让用户使用起来。从技术到应用之间,其实有着一个巨大鸿沟。这为后来周健思考让Agent学习专家知识并落地,埋下了伏笔。
第二段经历是2019年,他在PRA(机器流程自动化)厂商弘玑担任CTO,聚焦于从自动化的视角提升生产效率,但正所谓没有一个超级人能够处理所有的系统,也没有一个超级系统能处理所有的人,在RPA的实操过程中,由于员工缺少专家经验,导致人和系统之间也存在一个巨大鸿沟。
现在回头看,弥补两段鸿沟的关键,正是AI Agent。AI Agent由于有大语言模型这个地基,既有了对业务的理解能力,又能自主执行任务,还能随着企业知识库的持续更新而持续迭代。
站在风口,澜码科技火速发布了自己的AI Agent平台——AskXBOT,该平台宣称要“让专家知识赋能基层业务单元”,周健在交流中告诉我,其实最重要的是——让3万-5万月薪的专家把知识赋能8000块月薪(这里泛指一线城市大学毕业生的能力水平所对应的平均薪资)的员工,使得他们具备1.5万月薪员工的能力。而更进一步看,澜码科技还有一个宏愿——
「未来一定会出现“一人企业“,这个“人“是广义的,可能是一个程序员,可能是一个专家,但无论这个人是什么职位,未来“一人企业“会解决业务扩张的资源瓶颈。」
既然走到公认的下半场,在未来市场格局中,竞争也不会少,甚至是剧烈。不过周健坦言,更看重其中的机遇。他说:
“大语言模型本身是一个通用型技术,它的厉害之处在于,大家都能基于大模型的原料,做出各种应用佳肴,也就意味着,大家站在同一起跑线上,市场随时都在重新洗牌。”
周健又用一个经典故事回应了竞争问题:
“两个人在森林里遇到了老虎,其中一个人赶紧从背包取下一双轻便的运动鞋换上,另一个人嘲笑道:‘你干什么呀,再换鞋也跑不过老虎呀!‘这个人回答:‘我只要跑得比你快就好了。‘”
而澜码这个命名意指“波澜壮阔的代码”,当浪潮来临,如何冲浪,才是澜码要考虑的事情。

01 不要神化大模型,数据是企业主拿捏大模型的核心
科技行者:ChatGPT出现后,相信会有人与你讨论大模型,大家问的最多的问题是什么?
周健:最多的问题有两个——大模型能发展到什么程度?或者是,大模型的边界到底在哪里?本质上都是围绕AI这根曲线会怎么走的问题。
我接触到的人普遍都会焦虑,尤其是企业主,他们基本认为几年内,商业主战场会变成AI赋能的业务,但他们又没有时间转型或缺乏技术背景,所以担心会被AI替代。
科技行者:那你当时的回答是?
周健:答案有两个维度。第一个维度是关于大模型的边界,大模型或ChatGPT是取了一个“巧”,它通过对话式的UI,让大家觉得好像它无所不能,但事实上不是。
我一般都会跟他们举例,计算机科学发展了70年,难道今天你给我讲,过去所有的技术都不成立了,只需要大模型这一种技术?这肯定不靠谱。
我还会再跟他们举例,比如怎么判断一个人是不是985、211高校毕业?怎么去做一个发工资的软件?这两件事都不适合用大模型,大模型被设计的初衷也不在这里,它明显是有一条边界,大家其实还没完全理解这件事。
第二个维度是关于企业如何规划大模型,大模型本身需要更多的数据去拓展,企业今天还有很多信息没有被数字化。哪些数据有可能被数字化,并且被利用起来,那么这些场景就会慢慢被解锁。但如果没有,不管模型牵引的参数是万亿参数,还是宇宙值参数,都没用,因为已有的算法离开数据是搞不定的。
比如员工的行为就还没有被数字化,这里“行为”可能是指泛化的,对企业来讲,它本身有业务流程的上下文,或者企业本身经营的上下文,有了上下文,员工的行为数字化之后,就能够更好地被利用起来。
至少按照现在已知的AI技术,机器学习、深度学习,它的模式需要大数据,所以这部分是未来潜力,又是企业主“能掌控”或是“能意识到大模型发展的进度条”的核心。
科技行者:如果说有人不完全理解这件事,那么关于大模型你听到的最大误解是什么?
周健:有人或许把大模型等同于AGI。我同意大模型的出现很让人出于意料的,我自己也有这一认知框架的阶段,可以理解,但不要把大模型当成了大脑,当成了神域,拒绝自己思考,必须得问神,在神的指导下才能去做,这就让我觉得以往的知识是白学了,这是很大的误解。
科技行者:当然,也有很多企业走过了认知框架阶段,到了实践阶段,大家都发布了自己的“大模型”,虽然有些是根据Meta的羊驼模型改的,澜码为什么不赶这个潮流?
周健:这关乎我们的定位,我们一开始就知道有两个定位——技术和应用,但对于创业公司来讲,刚起步时不可能两个定位都占。
澜码作为一家创业公司,还是遵循需求为王。从需求角度看,我们一开始定位就是贴着人的、贴着业务和用户的。如果未来人机交互被革命掉了,那么整个软件行业就没剩多少软件能跟人互动,澜码虽然现在还是一家创业公司,但我希望我们拿到“人与AI交互”的机会,所以这是定位问题。
定位拆解完之后,有很多工作要做。我曾经也在想,如果预训练大模型,未来应该做一个什么大模型,但从优先顺序看,起码不是现在该考虑的事。
其次,无论是从技术还是资本的角度,大模型本身很重要的是数据集,澜码还没有积累一个自己独特的数据集。此时此刻,我去预训练一个大模型的商业竞争优势几乎为零,所以我暂时不愿意分心去做大模型。
02 专家知识的数字化,是Agent落地的必要条件
科技行者:澜码做AI Agent的初衷是什么?
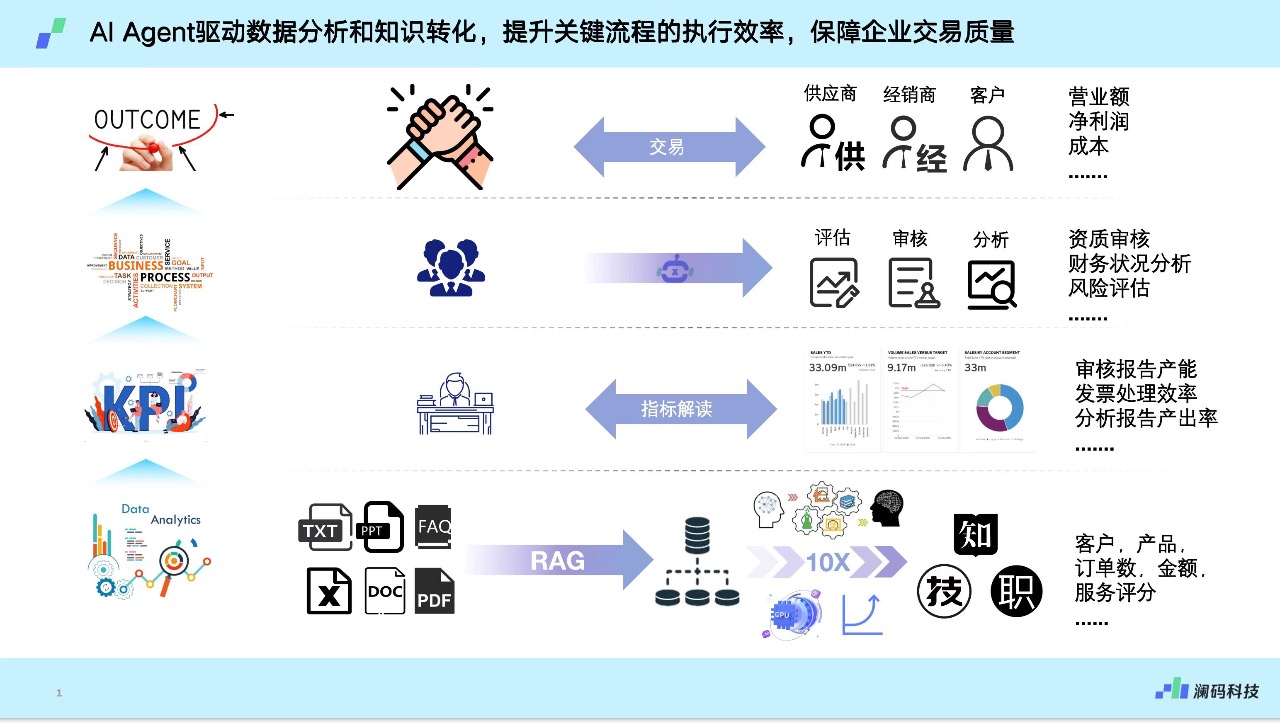
周健:是基于客户需求。我们接触到的客户,不管是大型央国企、还是银行保险、或是中等民企、甚至一些小型企业,都有同样的困扰——模型怎么那么贵?算力也非常贵。
今天中国100多家大模型公司,一年时间显卡价格翻了一倍,我们到底要做哪些准备?如何让大模型在企业中被用起来,去实际发挥业务价值?这就是澜码的业务逻辑——帮大家去解决问题。
在这个需求点上,我们发现国家电网、南方航空、国家管网、长江电力、中广核等好多“中”字头企业都有这个诉求,要入局,希望业务中有大模型。
所以我们的定位就是要做“大模型落地的首选厂商”,AI Agent是我们的切入机会。
科技行者:这存在一个先有鸡还是先有蛋的问题,是你们先看到央国企的需求,还是先有了AI Agent战略?
周健:我们先有AI Agent的战略。
科技行者:那就存在教育市场的情况了,另外你们是怎么让Agent平台自身更快落地的?
周健:首先我们对平台的能力有预判,一定要找到相应的场景,比如教育行业的评测场景,包括对话式的、政策解答等,也相当于找到了标杆客户,而且我们本来就有一些顾问是了解这个行业的。
这样一来,就会比市场上“声称要做AI Agent的厂商”明显更有穿透力些,从客户有兴趣,到他想要买,有加速转换的过程。随着标杆客户的Agent做出来之后,我们的平台越来越成熟,就会吸引更多客户,就是这么一个顺序。
科技行者:或许在这个过程中会有人质疑,AI Agent跟RPA有什么区别,可能我刚用上RPA还没完全普及呢,现在又出来了AI Agent,况且还存在一个迁移的问题,导致我会不会沦为技术的小白鼠了?
周健:我先讲一个企业内部的常见现象——信息化也好,数字化也好,企业发展过程中造成了大量的烟囱式系统,生产力受到了严重束缚。
RPA(机器人流程自动化),是通过UI自动化的办法去操作各种系统,它能够通过低代码把那些组件“拖、拉、拽”,把对不同系统的操作连接起来,形成一个可以被自动化的操作流程,其实更多是在做操作流程的自动化。
但RPA最大的问题是,对于所操作的数据或内容,是无感知的、不理解的、也无法推理。举个例子,一个财报,它在配置时说“第五行是收入”,如果说“第六行转成收入”,即使你写了“第五行换成第六行”,它还是不能理解。
AI Agent叠加上去的就是大模型的语言理解和推理能力,有了大模型,使得系统可以应用大量知识和真实世界的环境数据,如政策网站、股票实时信息、天气信息等,我们可以更好的把这些能力封装起来。
能力叠加之后,AI Agent可以作为一个连接器,连接管理者和基础员工、专家和基础员工、员工和员工,而且只要加算力,它就能够复制,它一天不止24小时,有30块显卡,它就有720小时,多一个维度来填充企业想做数字化转型时所面临的人和系统之间的空白,从而使整个企业的数字化系统变得更加智能,能够发挥出「新质生产力」的作用。
科技行者:其实相当于是从自动化到智能化的一个跃迁。
周健:是的没错。
科技行者:具体到澜码的AI Agent产品AskXBOT,它的产品逻辑是怎样的?
周健:从澜码的AskXBOT平台的理念来讲,我们分成三步走:第一步,专家知识的数字化;第二步,基于CUI的柔性交互;第三步,领域知识的循环沉淀。
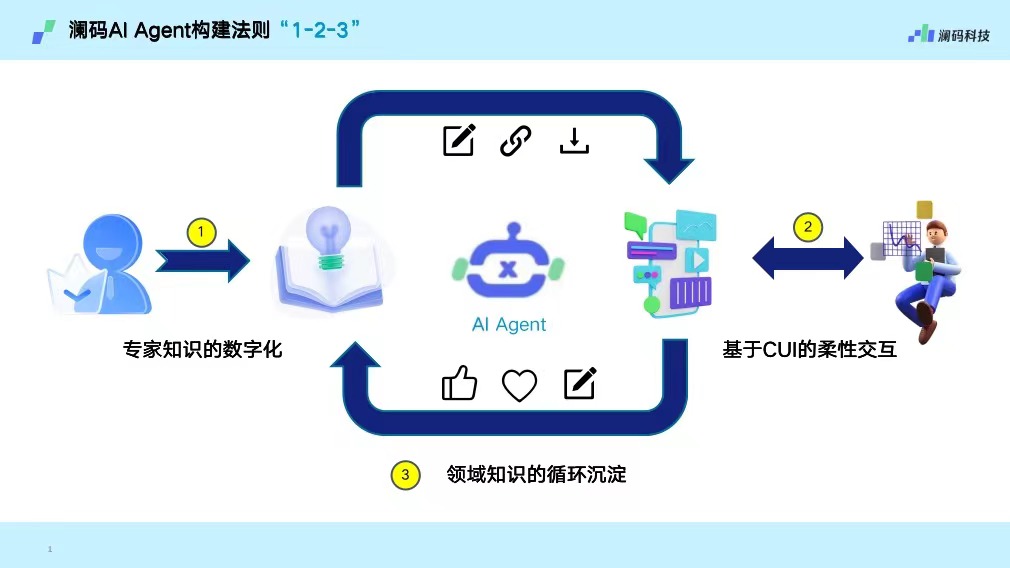
第一步「专家知识的数字化」。其实很多企业在这部分并没有做好,比如我们某个客户,我们想要协助他的表格实现类似于Office Copilot的功能,客户拿出来5000个API,我们一调,准确率只有10%,但是仔细一看,原来是程序员写的对于API的描述有错误。AI Agent拿着一个错误的描述,当然不可能正确表达。
同样,我们帮一些银行去做数据中台的落地,想让业务人员直接通过对话生成BI报表,但经常发现它内部的知识中,不同的领域里,同样一个单词有着不同的意思。那么AI Agent遇到这个情况,就需要反问一句,它到底是“个人金融的单词”还是“公司金融的单词”?
就像信息化是数字化的前提,数字化是智能化的前提,没有弯道超车的可能性。所以,如果我们没有把专家知识数字化下来,AI Agent的发展会面临很大挑战。
我们认为,专家知识会分成两种,一种是更偏自然语言、可被编码的知识;另一种是经验性的知识。比如我一直举例:“工作稳定”,估计没有一个招聘专员能够用自然语言描述清楚“什么叫做工作稳定”,它肯定是经验之谈,所以自然语言编码+大数据,才是一个完整的「专家知识」。
第二步是「基于CUI的柔性交互」。业界有一个共识,GUI(图形界面系统)已经是上一代的界面,而CUI(对话式界面系统)会作为一个新的交互形态。如何让机器去适应人?一方面是需要机器去澄清、去反问,另一方面要根据用户的习惯去进行调整。
有了这个环节,新一代的AI平台软件,被使用起来的门槛就大大降低了。否则,就像过去的传统软件,比如一些ERP、CRM都做的很好,但是当时由于缺乏自然语言理解能力,所以无法应对在各种上下文、各种场景之下的用户各种各样的问题,这其实也是我们在实际落地当中,客户会对我们提出的要求。
第三步叫「领域知识的循环沉淀」。当我们的AI Agent作为连接器,能够把专家知识和一线业务人员连接起来之后,专家知识实际上就有了更大的用武之地。
比如我们有一个客户是做零售企业的咨询,过去他的专家ETN咨询一个客户,那现在有可能同时有100家、1000家、甚至1万家店长问它问题,那么专家知识就得到了1万个人的实践,然后由于问题被记录下来,专家可以进一步去分析、总结,并提出新的洞见。
这三个步骤就是澜码构建AI进程的法则。
如果要再具体拆解,澜码科技“AskXBOT”由四大模块构成:设计器、知识中心、使用端、管理平台,是基于LLM的Agent与工作流设计、开发、使用、管理、知识沉淀的一站式平台。

03 公司拥有自己的大模型,是未来在竞争中的立身之命
科技行者:刚才您提到一个宏愿,澜码想成为大模型落地的首选厂商,怎么简单的理解落地的价值?
周健:就是基于大模型,通过人机协作,把专家知识教会AI Agent,然后去赋能高级新手。直白而言,是让3-5万月薪的专家能够把知识赋能给8000块月薪的员工,使他们变成月薪1.5万,这是我们此刻能实现、能落地的。
如下图,著名的“德雷福斯模型”研究人类掌握技能的5个阶段依次为——「新手-高级新手-胜任者-精通者-专家」。
高级新手跟胜任者最大的区别就在于,高级新手可能记住了公司的培训技能,但他因为不如胜任者有经验,所以他不知道在什么场景、用什么知识,而这恰恰是专家擅长的,他的知识能够通过AI Agent辅助高级新手,从而使高级新手实现加快胜任任务的过程。这是今后的趋势和需求。

我相信企业不难找到一个专家,难的是怎么让专家培训内部的业务人员,比如零售业导购、营业厅话务员等,企业要扩张,很多时候是靠增加人,但它没办法用可控的成本去雇到足够好的人,而我们能够实现专家知识的数字化,能够赋能到基层的业务单元,这是澜码在三年之内想要解决的问题。
我们帮企业赋能基层业务单元,能带来直接的好处——「增收」。企业内部、特别是大企业,一定会有大量基层业务员工在重复做着各种事情,没记错的话,中国全行业应该有2000万零售人员、有1000万保险代理、有几百万银行理财经理、有几十万猎头、有几百万程序员,其实都可以通过AI Agent专家知识去赋能。所以,算力的增加就带来生产力的提价。
科技行者:这就涉及到另外一个问题,企业的专家可能是核心竞争力,是宝藏,如果把专家知识或数据全部数字化,如何保障企业数据安全?或许有些企业一边想拥抱AI,但又怕自己的数据在大模型里被拿走了,从而导致束手束脚?
周健:我能理解,但我也认为不必担心。其实大模型最重要的是知识,专家知识的数字化是AI Agent落地的必要条件,所以知识比数据更重要。
有些「知识」可以通过编码变成自然语言,但有些「经验性知识」是编码不出来的,所以今天摆在每个传统企业面前的,是怎样把知识管理好,怎样保证企业不被单个专家绑架,有能力把它沉淀到自己的IT系统里,或者能够被复用,能够去传承,这才是今天最大的命题。
传统企业可以要求你数据库里的数据不被大模型拿走,但关键是你有哪些数据能够拿出来,让澜码AskXBOT去使用其中的知识,从而能够放大企业的优势?当然,有些敏感场景,比如报价信息、薪酬信息、交易数据,这些数据不能交出来,但其实外围的系统也用不起来这些数据。
我曾经回答过一个问题,问的是3、5年后,每个企业都要做一个自己的大模型吗?我的观点是,独角兽(10亿美金估值)以上的公司都得有一个自己的模型,这是企业的竞争优势,是它在市场竞争中的立身之命。
另外,传统企业今天要拥抱AI,最重要是把知识沉淀下来,战略是把核心的差异化优势,通过大模型的「智力基础设施」放大,并且迭代闭环,至少能立于不败之地。这部分一定得私有化部署,肯定要找像澜码这样的厂商帮助你去做。
科技行者:换句话说,我们之前跟一些创业公司聊,他们普遍觉得AI技术是一方面,更重要的是行业的know how,各行业专家的知识数据,各种senior员工的经验之谈,对于这家公司,或者对于公司数据来说,都是一个差异化优势,澜码相当于把企业的差异化优势封装到平台里。
周健:是的。
04 硅谷是一个热带雨林,国内大模型创业有机会重塑局面
科技行者:咱们有对标的公司吗?竞争开始了吗?
周健:在国内较少,在国外有一些,比如Fixie.ai公司,还有Relevance AI公司最近融了1000万美金,他们就是在做AI的低代码平台,跟我们接近。
科技行者:那咱们跟他们的区别是什么?
周健:硅谷跟国内有很大区别,硅谷本身是一个“热带雨林”,上下游关系很容易配合起来,他们会在某个专精的点上做很深。
但是在国内,这个生态还不太成立,很多企业老想自己做(尤其是软件企业),所以为了把AI Agent生态构建起来,我们一开始必须把所有事情都做,然后再慢慢把不该做的事情让出来,退回到自己有核心竞争优势的地方,这也是今天国内做To B企业服务创业较难的事。
科技行者:意思是从大环境来看,其实在国内做To B企业服务创业比国外更难?
周健:这得分开来看。一方面,国外的SaaS已经很成熟了,国内所谓的IT预算,更多是在央国企或政府,民营企业的IT预算相对于整个大盘子来讲是少的,生态还不完善,原因就在这里。
另一方面,国内企业管理的科学化方面,央国企还是更强一些,民营企业还差的很远,那么在没有管理科学化的前提下,就很难去谈“我们再做一个软件信息系统把它给固化下来”,这是国内相比较硅谷去做这件事情更难的点。
不过,问题也是机遇。在海外,像微软、Salesforce这些大厂,已经把大的场景或数据都拿到手了,这就跟国内的C端已经被互联网大厂守住的情况一样;但是在国内,金蝶、用友、金山办公等,它仍然还只是一个单一场景,这也是今天出现颠覆性机会的原因,创业公司有可能去重塑局面,今天随着AI大模型的能力不断指数级上升,是有机会重塑企业流程的。
科技行者:正好说说中美AI创业的差异吧,你正好两边都看过、做过。
周健:这可能要谈谈时代背景了,有人说未来中美一定会有两套操作系统,或者说是两个生态。不过现在看,一个区别是中国一定更强的是应用,因为无论在哪个时代,市场需求都是很重要的,现在的市场环境下更是如此。
如果比较技术方面,我们可以先看一下大模型本身的特点。它是一个技术突破,技术突破本身会有极大的不确定性,即使像谷歌和微软砸了那么多钱,最后技术突破竟然还是OpenAI带来的,所以它有很强的不确定性。
在这方面,美国市场或许因为所处阶段,导致了它能够不计得失且不计短期利益的去投入。而中国最大的好处是,它是能统一大市场,今天在应用侧,硅谷跟中国创业的水平其实没差多少,这挺难得,过去在企业服务里,中国平均落后美国两三年,但现在当底层重新发生非线性增长时,中国是很可以的,因为我们的场景、需求、数据都在那。
AI领域还有一个有意思的点是“普惠主义”,真的在AI Agent确实有机会实现“普惠”,这个过程代表社会技能的转移,所以我其实很看好在中国相关创业机会。
科技行者:所以咱们暂时是不会考虑出海?
周健:对,我觉得肯定不是大力去出海。
科技行者:突然想到,澜码的底层大模型用的是哪一个?
周健:我们有一个框架,保证什么模型都能用,用的最多的肯定是OpenAI,因为它目前是最好的。当私有化部署的时候,你需要去换一个,挑一个测试出来相对较好的模型就好了。
科技行者:有看到与OpenAI相媲美的吗?
周健:有快要追平GPT 3.5的,但我觉得离GPT 4都还有距离。
科技行者:对于任何一家公司来说,PMF都是很重要的,你是怎么考虑澜码的PMF的?
周健:PMF很重要的是要找到足够好的客群,并且通过迭代,找到最小成本去迅速复制的路径,它脱离不了一个背景,就是所谓的技术采纳曲线,或者是以前所谓的跨越鸿沟。
今天的大模型创业,有所谓的趋势性周期,过去任何一个单点的创业,不管是技术、客户、行业,整个环境是稳定的,所以创业者只要有想法,或有解决方案,都可以聚焦去做。但今天情况变了,因为底层的大模型技术一直在快速演进,某种程度上这对我们是一个大挑战。
另外,整个市场对于大模型的认知也在变,这是一次新的社会实验,每个行业、部门、角色,对大模型的看法都会随着时间而发生变化。
当前澜码所处的阶段属于Solution fit(解决方案适配阶段),是在做加法,就是客户要啥、缺啥,我就补啥、就去做啥,这个阶段相对容易。但是之后到了PMF阶段,如果要跨越鸿沟,关键是要做减法,从客户角度去研究我们的产品处于哪个阶段。要做解决方案,要加大市场口碑,要做减法,还要降成本,才能普及让用户用起来,其中有很多细节的地方。
科技行者:咱们PMF整个过程需要多长时间,才能迎接下一个海浪?
周健:我们已经有十个标杆客户,陆续都在交付了,所以整体已经完成了PMF。
下个阶段我们需要打磨的是,到底如何用客户听得懂的一个卖点,击中他的心窝子。好在目前整个市场培育不需要我们操心,很多央国企是有硬性要求的,包括很多CIO已经成立了专门的大模型组,有KPI规定是一定要落地的。
所以接下来,如何找到那个直击市场痛点的抓手,而且是普适性的、规模化复制的、可以标准化的,是我们在打磨的一个重点。
比如最近有个项目,我们跟客户领导聊细节,客户提了一个很简单的诉求,但中间经过了很多轮沟通,最后客户直接说,你别跟我扯那么多技术,我是小白用户,你直接告诉我,什么能做,什么不能做,三句话不能再多了。
我觉得很合理,所以我就想把我的产品打造成小白用户就知道怎么做,今天大模型最大的好处是,它使得机器可以适应人,不需要人去适应机器。
05 创业一边要重视它,一边要把它看轻一点
科技行者:你之前在依图和弘玑是顶级的技术专家,现在又是创业公司的领导者,怎么看待角色的转变?
周健:首先我觉得自己还没有到“家”的地步。再者回答角色转变的问题,第一,视角很不一样,CTO或技术人很多时候是更高质量的做事,而对于CEO来讲很重要的是选对人和方向。
我刚创业时,觉得啥都能干,但显然我不能啥都干,“怎么选择”就是一个很大的问题,选择就一定有价值的标尺。什么叫做好?什么叫做坏?过去作为技术人员的“好”和“坏”,跟现在商业世界里的“好”和“坏”,完全不是一回事。
技术的好坏可能是世界级、领先性,而商业的本质是生意,你要给客户提供价值,要有竞争优势,要有壁垒。所以技术是向内的,CEO是向外的,我现在基本70%以上的时间在外面,只有30%的时间在公司里。
科技行者:既然选择正确的方向很重要,也就是说创业者的预判、视野、格局都很重要,咱们怎么去塑造自己的这些能力?
周健:对。我越来越觉得,去考核一个CEO看两方面:
其一,认知是一个最大的障碍或瓶颈,所以创业者一定要有快速学习的能力。其二,心态也很重要。
这里有三个阶段,第一个阶段是缺知识,你要补知识;第二个阶段是方法论,你知道怎么学习(这两个阶段基本上能创业的CEO肯定都经历过了);第三个阶段也是很难的,就是把自己的认知,不断的去审视,把错误的假设,不断的修整掉,本质上这要保持一种“空桶心态”。
怎么跟自己和解,是心态上的第一步。第二步则是要更积极的发现自己假设错误的地方并修正,特别是在今天的新摩尔定律时代,大模型相关的创业领域变化太快。
我开玩笑说,知识或观点的半衰期可能只有一个月,我沉淀出来的假设可能很快就会被修正,但是反过来看也正是因为如此,创业公司才能跑得快,才能跟大厂巨头在同一起跑线上。
作为CEO,上面提及的这两件事情,是蛮本质的问题,如果不解决,就会成为瓶颈。
科技行者:说到心态,现在特别是技术人员,程序员或开发者群体里,特别流行一个词叫35岁恐慌,这可能是一个魔咒,你认为这些人群的职业成长应该何解?
周健:我理解“35岁魔咒”,本质上是大家一直在重复自己的工作,导致当底层环境发生变化,你不知道该怎么办了。
我当年在谷歌,很快就做到了一个模块的负责人,管理十几个C++代码,大概三、五千行代码,全谷歌的人如果要改这些,都得通过我的同意才能提交,但当时的我仍然很恐慌,担心如果代码被换了,我该怎么办呢。
所谓的“35岁魔咒”,从宏观角度来讲,就是不同层级的人,当他到达某个局部高峰,又不愿意往外走,或者说他不知道应该怎么往外走,怎么去突破他原有的瓶颈,发现外面的世界,那么他永远无法到达另一个高峰。
我有个习惯,是看自己能否把某个参数乘以10。假设你现在的系统是高并发的,你原本每天要发一个版本,但如果要你每天发十个版本,你应该怎么办?类似这种假设性的问题,很容易帮你发现自己思维当中的“黑盒”。
这个方法叫做迁移学习,如果你有能力把你已有的经验换到其他的环境里面去,这时候你是不怕“35岁魔咒”的。
科技行者:你35岁的时候是在谷歌吗?
周健:我1999级入学上海交大,2002年拿了ACM世界冠军,2006年硕士毕业,当时我拿了三个offer:一个是微软亚洲研究院,一个是谷歌,还有一个是在上海的MSN。
那时候谷歌刚进入中国市场,因为我有亚洲首个ACM冠军团队成员的背景,对谷歌有吸引人才的宣传效果,当时微软亚洲研究院的沈向洋打电话给我,我去北京和沈向洋当面One&One,但那时我觉得谷歌更有互联网思维,所以选了谷歌。
我毕业后头三年在谷歌,后来三年在阿里,我在2011年离开阿里的时候是P8,基本上已经过了所谓的35岁,所以很清楚怎么应对“35岁魔咒”了。
科技行者:那么作为连续创业者,对于其他创业者,有什么过来人的经验之谈?
周健:从岁数上来讲,我已经40几岁了,可能稍微年长一些,可以总结一下,我觉得创业要有底线思维。
创业很有意思,但要把生活跟工作分开,创业本身只是一个手段而已。今天澜码所遇到的机遇是我的人生机遇,如果错过了这个机会,我可能这辈子也拿不到更好的机会了,但我仍然觉得这只是人生过程中的一段经历而已,千万不要因为某些事情,而出现这样那样的执念,就孤注一掷,因为风险随时存在。
我十年前创业过,当时最后把公司关了,关闭公司的过程很痛苦,好在当时没有什么其他后果,但是心态要放平和,创业一边要重视它,一边要把它看轻一点,得掌握一个度。
虽然我十几年前创业失败了,但有点像乔布斯讲的——可能在那一刻,觉得它是一个curse(诅咒),但是当你迈过去了,就是一个bless(感恩)。
科技行者:今天我们一直在谈大模型,最后再总结一下对大模型的判断吧。
周健:AI Agent今天最大的问题不在应用层,而是大模型本身算力的要求太高,但现在大模型公司对于算力的小型化已经做了很多,2024年基本可以过平均线,2025年可能就普遍可用了,到那时,谁在“裸泳”就很明显了。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

从技术乌托邦到问题显微镜,AI for Good正在落到实处

北沟村的幸福蝶变:一场时间与技术的乡村交响

DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮

阿里云李飞飞:将大模型,装进数据库里

周雅
主编
