 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
阿里云李飞飞:将大模型,装进数据库里

作者 | 金旺
来源 | 科技行者
预计2027年,云数据库将占据整个数据库市场份额的70%。
这是Gartner在2019年给出的预测数据,从Gartner最新的统计数据来看,截至2023年年底,云数据库在整个数据库市场中占比已经高达61%,这时的云数据库已经成为大势所趋。
与此同时,人工智能技术的骤变,开始影响数据库产业,数据库再次成为人工智能从技术到商业化的一个关键平台。
Gartner高级研究总监顾星宇指出,“到2028年,80%的生成式AI业务应用将在企业现有的数据管理平台上开发,从而将实施复杂性和交付时间缩短50%。”
作为云数据库的坚实拥趸,阿里云智能集团副总裁、阿里云智能数据库产品事业部负责人李飞飞则断言,“第一波人工智能浪潮是由Native AI群体掀起,但在人工智能进入下半场后,本质上已经回归到系统领域,回到了工程化问题上。”
也是在这时,阿里云PolarDB看到了他们的机会,进行了又一次产品迭代,也面向人工智能推出了PolarDB-Model as an Operator。
01 千机集群打出一个世界纪录
2月26日,在2025阿里云PolarDB开发者大会上,阿里云官宣,PolarDB登顶全球数据库性能及性价比排行榜, 并刷新了TPC-C性能和性价比双榜的世界纪录。
TPC-C测试,是由国际数据库事务处理性能委员会(TPC)组织制定的模拟电商订单服务场景,针对数据库在线事务处理(OLTP)系统性能的一场长达40小时的极限基准测试。
其中,数据库系统需要在极限压力下运行8小时以上,在这期间,tpmC的波动率不能超过2%,还要保证数据正确率为100%,与此同时,测试模型还会模拟各种硬件故障情况,参与测试的产品需要确保数据不丢失,并能快速恢复正常性能。
这一基准测试历来也有着数据库领域“奥林匹克”之称。
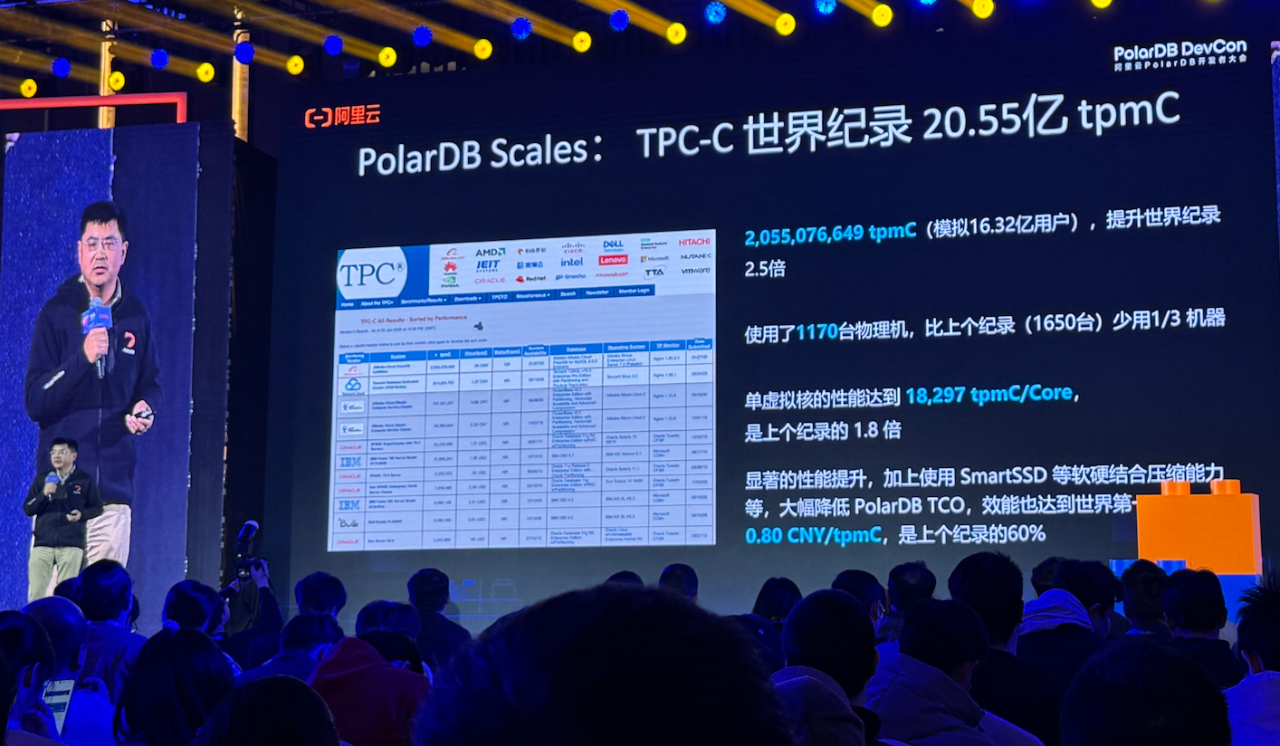
正是在这样一个极为严苛的数据库测试中,阿里云PolarDB团队在2025年1月27日用1170台物理机搭建了一个PolarDB集群,这个集群拥有2340个PolarDB主节点和2340个PolarDB从节点,最终支撑1.6亿家商店、16亿用户跑出了每分钟20.55亿笔交易(tpmC),刷新了TPC-C性能排行榜,打破了世界纪录。
在这次TPC-C测试过程中,阿里云PolarDB数据库还刷新了另外三项成绩:
第一,使用物理机数量相较于此前纪录保持者(1650台)少了三分之一;
第二,单虚拟核性能达到了18297tpmC,是此前纪录保持者的1.8倍;
第三,单位成本0.8元(price/tpmC),是此前纪录保持者的60%。
为什么PolarDB能在这场全行业瞩目的基准测试中打出这样的成绩?
这其中的原因之一是PolarDB集群网络部署从去年的25G Lossless RDMA升级到了100G Lossy高性能RDMA网络,基于这样的RDMA网络,PolarDB团队可以搭建连接数千台,乃至上万台物理机的集群,并实现了高性能事务一致性执行能力,多节点复制能力也由此提升了1倍。
具体到TPC-C测试中,这样的高性能RDMA网络带来的一个变化是,PolarDB的上千台物理机集群跨机业务对性能的影响得以被控制到7%以内。
据阿里云智能集团数据库产品事业部PolarDB MySQL及PostgreSQL负责人杨辛军在发布会上透露,“PolarDB这次打榜最终达到的20.55亿tpmC成绩并不是我们的极限,实际上,PolarDB可以跑得更好。”

TPC-C是一个相当真实的情景模拟,它会模拟用户在电商进行购买操作,这其中,每个商店能够支持的客户人数和交易速度都有限制,每个商店仅支持10个虚拟用户同时进行交易,商品数量也有一定限制,因此,最终交易性能与商品数量相关。
据杨辛军介绍,“我们打榜后发现,我们的限制并不是单机性能,而是存储,由于我们当时并没有购买足够的存储资源,如果当时我们购买了更更存储资源,我们打出的成绩理论上可以再提升,在相同物理机和节点数量下一直可以提升到28亿tpmC。”
而之所以会有这次打榜,杨辛军告诉我们,“这其实相当于是一次检阅,在PolarDB的新升级的硬件上线给所有用户用之前进行的一次检阅,而这些硬件在打榜后,最终将会进入商用市场,为用户提供服务。”
一并在这次发布会上发布的,不只有随PolarDB打破世界纪录并将进入市场的数据库集群,还有阿里云第一个CXL Switch内存池数据库。
02 打破“内存墙”,CXL-Powered PolarDB亮相
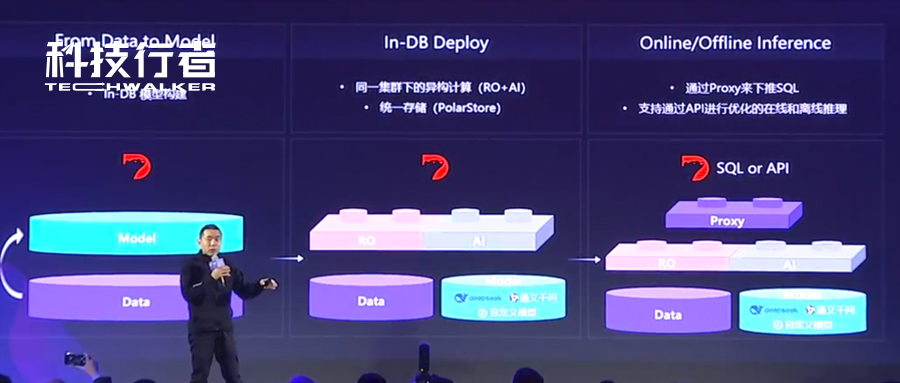
作为新一代云原生数据库,PolarDB的独特之处在哪里?
李飞飞给出的解释是:
“PolarDB通过三层解耦架构,在数据中心规模上实现了冯诺依曼架构,将拥有成千上万台服务器的数据中心变成一台实现了计算、内存、存储三层解构的云原生计算机。”
基于这样的技术架构,PolarDB此次正式对外预发布了第一台基于CXL Switch的数据库专属机型。

什么是CXL?
CXL是基于PCIe一种新型高速互联技术,旨在解决计算系统中数据处理延迟、速度减慢和可扩展性问题,提供更高的数据吞吐量和更低的延时的接口标准,可以连接CPU、GPU、DRAM、存储设备,解决CPU与设备、设备与设备之间的内存鸿沟。
在当下大模型时代,内存发展与算力增长速度的不匹配导致了“内存墙”问题的出现,基于CXL Switch的数据库专属机型在硬件上契合了PolarDB的三层解耦架构,并为解决大模型的“内存墙”问题提供了解决思路。
据杨辛军介绍,“以配备单根256GB内存、连接7台物理机的CXL Switch内存池的PolarDB数据库为例,一个机柜可以支持16TB的内存容量,这时,每台物理机都可以使用这16TB内存容量。”
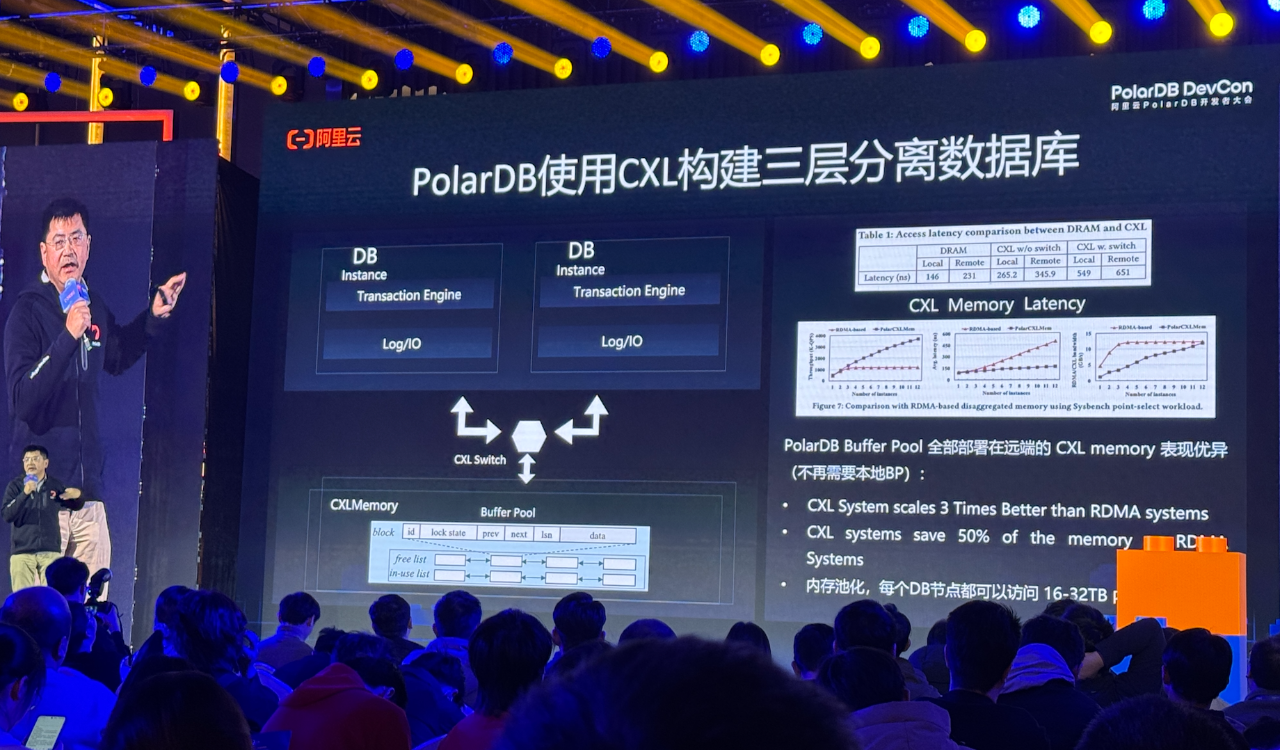
PolarDB通过使用CXL技术构建三层分离数据库,部署在远端的数据库并没有因为跨机和跨地域导致数据库性能下降,反而扩展性提升了3倍,而通过远端数据库替代本地数据库的形式,数据库成本也得以下降了50%。
对于基于CXL Switch内存池化的机型,李飞飞在接受媒体采访时特别强调,“我们并不是要做线下市场、做一体机,这些机型最终都将会用到公共云上的PolarDB专属资源池构建中。”
PolarDB在Kernel层有各类压缩算法,但李飞飞认为,“仅做这些还不够,PolarDB还需要在磁盘SSD的控制上做优化,由此才能真正做到软硬件协同创新。”
李飞飞指出,“云原生是必然趋势,任何系统向前演进仅做软件创新是没有未来的,一定要做软硬件协同创新,DeepSeek证明了这一点,PolarDB的突破同样证明了这一点。”
至于此次在发布会上亮相的CXL-Powered PolarDB,杨辛军在发布会也强调,“这次基于CXL Switch内存池化的PolarDB数据库只是预发布,还没有正式应用到生产环境中。”
据悉,接下来PolarDB团队还将会在GPU+CPU异构资源池上继续优化,满足大模型对于异构算力的应用需求。
03 将大模型,装进PolarDB里
随着DeepSeek在年初的开源,大模型正式进入到了人工智能应用爆发的元年。
谁能抓住这波人工智能应用爆发的机会?
李飞飞认为,“只有那些将大模型更好地与现有业务流程、数据流程结合,把成本降低、把资源优势打满、让数据真正发挥出价值的企业,才能抓住这波机会。”
自2025年,以大模型为代表的人工智能时代被划分为上下半场,上半场的竞争焦点是大模型的预训练,接下来大模型的预训练将会呈现出在线化、集中式的趋势,而下半场本质上又回到了传统的系统和工程领域。
对于数据库厂商而言,“模型即算子”已经不再是一个“if”,而成了正在发生的事,也是在此次发布会上,PolarDB-Model as an Operator正式对外发布。

李飞飞在发布会上介绍称,“我们现在已经可以把包括大模型在内的各种各样的模型作为算子内嵌到数据库引擎中,这样为我们从数据中发现价值带来了便利,为传统OLAP的意义和方向会因此得到极大的拓展。”
这是李飞飞坚定看好的发展趋势。
为此,PolarDB团队将包括通义千问、DeepSeek等在内的大模型作为算子内嵌到了PolarDB数据库中,利用PolarDB的三层解耦架构和多主多写能力弹性伸缩出人工智能推理节点。
这一波操作下来,极大地简化了企业部署和应用大模型过程中数据管道,企业不再需要将数据转移到专有推理平台上,将推理结果拿回来再进行业务判断。
实际上,PolarDB-Model as an Operator不仅仅是将大模型内嵌到了PolarDB数据库中,还针对大模型做了一系列优化。

杨辛军告诉我们,“由于PolarDB特有的三层解耦架构可以实现内存的解耦,部署在PolarDB中的大模型就可以将CPU和GPU的资源充分利用起来,在同等GPU算力条件下,部署在PolarDB上的DeepSeek并行用户访问量可以提升35倍。”
与此同时,将大模型装进数据库也避免了企业私有数据出域,为企业数据安全和大模型应用提供了一个新思路。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

数智风起辽沈:从矿山到低空,看老工业基地的智能新生
这里曾是中国重工业的摇篮,装备制造业的轰鸣声响彻几代人。如今,这片土地不再只依赖钢筋铁骨,而是主动拥抱数智化的浪潮,用算力和算法书写东北振兴的新篇章。

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路
陈立武的到来,像一颗石子投入平静湖面,激起涟漪的同时,也让人好奇:这位65岁的“半导体老兵”能做到什么程度?
 2025-03-20 10:11
2025-03-20 10:11黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员
在GTC2025大会上,英伟达CEO黄仁勋在一场至顶科技等全球媒体共同参与的记者会上表示, AI正在成为一个全新的制造业。AI不是传统意义上的软件开发,而是一场需要基础设施、能源和资本投入的产业革命。


数智风起辽沈:从矿山到低空,看老工业基地的智能新生

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路

黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员

AMD如何推动AI PC普及?

金旺
主编
