 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
Facebook挑战赛:利用AI检测恶意图文,还有很长的路要走
科技行者 5月15日 北京消息:

▲ 图:Facebook认为,要确认「恶意图文」,就需要计算出“无害短语”和“无害图像”之间的交集函数。Facebook用人工示例来说明这个问题的本质所在。
恶意图文(Meme,又译迷因或模因),是一种基于宗教或种族等特征的、用于贬低他人的文字和图像组合。Facebook认为,恶意图文对于机器学习程序而言是一个有趣的挑战,机器学习在短时间内还找不到完美的解决方法。而Facebook最新研究表明——深度学习的人工智能形式在“检测”恶意模因的能力方面远远落后于人类。
Facebook本周公布的一篇题为《恶意模因挑战:在多模式模因中检测仇恨言论(The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes)》的研究论文,文章搜集了网上(包括Facebook上)的10,000个恶意模因,建了个示例数据集,作者比较了各种最先进的深度学习模型检测及人类检测结果。
论文的主要结论是:“还有很大的改进空间”。作者发表博文《Hateful Memes Challenge and Data Set》(https://ai.facebook.com/hatefulmemes)概述了这项研究。另外几个Facebook研究人员发表的另一篇博文《AI advances to better detect hate speech》(https://ai.facebook.com/blog/ai-advances-to-better-detect-hate-speech)广泛地探讨了AI检测仇恨言论的话题。
他们就这个有趣的机器学习课题发表博文,是因为「恶意图文检测」只是作者提出的“多模式”学习的一个示例。科学家研究的多模式,就是结合各种机器学习程序,处理两种或多种信号。博文里的例子则是对文本和图像的处理。
作者在博文里提到,臭鼬图片本身没什么恶意,文字“喜欢你的味道”本身也没有恶意,但将二者结合起来就“恶意”了。因此,计算机程序不一定能用一个函数计算出文字和图像的交集函数,该交集是一种诽谤或其他仇恨言论。
他们做的测试非常简单。作者从不同地方(包括Facebook)收集了100万个模因样本,他们移除了任何违反Facebook服务条款的模因,例如含色情内容的模因,结果剩下162,000个模因。然后,他们重新将文本复制到一张新图片上,重新创建了模因,新图片来源是与库存图片授权公司Getty Images合作获得的。这样做是为了消除原始模因创建方式中的特质,这种特质可能会扭曲测试结果。
然后,他们让人工审核人员判断这些模因是否内含“恶意”,一旦有多数人对同一个模因意见相同,就留下这个模因,最后得到10,000个模因,这10,000个模因是机器学习的训练和测试数据集。他们还纳入了“混杂因素”, 混杂因素指那些意思反过来的模因,就是原本是“恶意”的模因,然后转换成“赞赏”或“恭维”的模因。作者写道,这样做是为了扰乱机器学习系统里可能存在的“偏见”,“偏见”会令机器学习系统轻松地评估模因的恶意程度。
文章没有列举模因的实际例子,文章认为这样做不适合重新定位内容,那些希望了解模因的人可以下载数据库(https://github.com/facebookresearch/mmf/commit/ef04cc2de0cf58e3e31c662ed49f679d876cf9a3)。相反,作者使用的图文是暗示性复制品,例如本文上图里的模因,那个文本是“喜欢你今天的味道”的臭鼬图片。
然后,一个人类“专家”复核者需猜测面前每个模因的恶意度,每个模因在这里成了该测试的人类基准。不同的机器学习计算机程序,都必须做同样的事,计算恶意度。
人类在估测“模因”恶意度的平均准确度得分为84.7(满分为100),最佳的深度学习模型得分仅为64.73。
模因数据可以从网络下载,是Facebook《模因挑战赛》用的模因数据集,《模因挑战赛》模因数据集有点仿ImageNet数据集的意思,ImageNet数据集几年前推动了图像识别的发展。Facebook通过托管在线挑战的合作公司DrivenData,为参加挑战赛人士提供了总计100,000美元的奖励, 一等奖50,000美元。
Facebook表示,挑战赛会是今年NeurIPS AI会议的挑战之一。有关录入日期等数据可从DataDriven的网站上获得(https://www.drivendata.org/competitions/64/hatefulmemes/?fbclid=IwAR2NFrckKiT9yiQbARrK7AD2g_Cq_HTCm7J-kuOI9PEEfk1YHK3uCq5ILNI)。用于挑战赛评估参赛程序的模因示例,是未在模因数据集里出现的模因。
文章里提到的测试里目前得分最高的模型是ViLBERT和Visual BERT,ViLBERT是佐治亚理工学院的Jiasen Lu及其同事是去年提出的(https://arxiv.org/pdf/1908.02265.pdf),ViLBERT模型技术将视觉和语言处理结合在一起;Visual BERT(https://arxiv.org/pdf/1908.03557.pdf)的作者是UCLA的Liunian Harold Li及其同事,也是去年提出的。
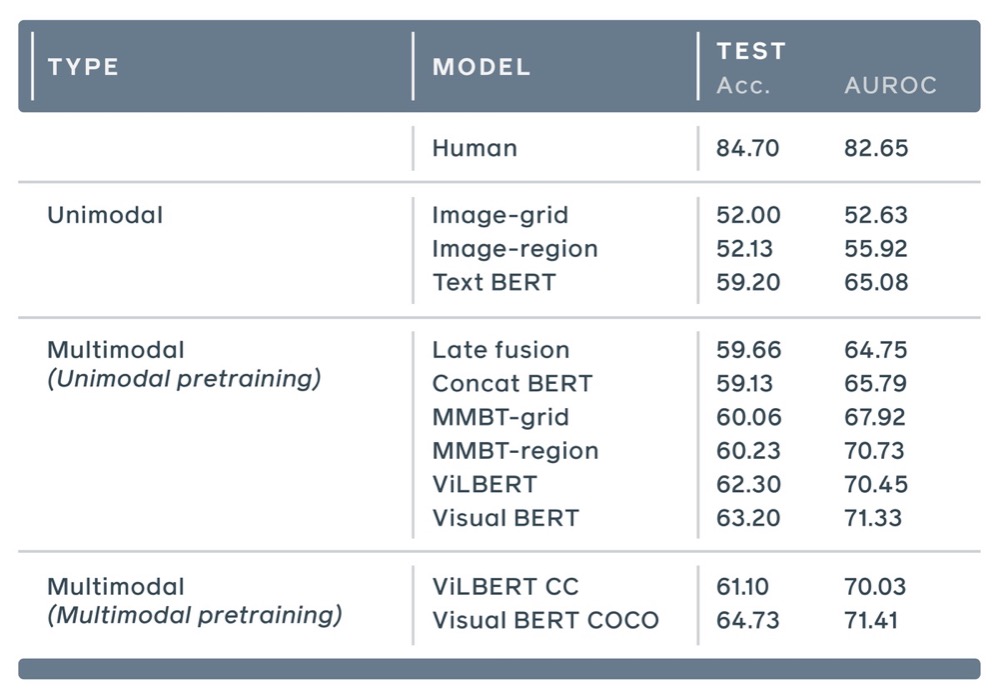
▲ 图:不同的深度学习模型计算模因“恶意”度以及人类估测“恶意”度的结果。性能最佳的模型是ViLBERT和Visual BERT,两个模型都是基于 “融合”文本和图像处理开发的。
可以从名字看出来,两个模型都是从谷歌的BERT系统派生出来的,而BERT系统则是基于“Transformer”方法进行语言建模。Kiela及其Facebook同事在测试中发现,在推导一个模因的恶意度方面,这些视觉语言联合体,比那些只看模因文本的模型要好。例如,与VisualBERT的64.73分相比,纯BERT模型的得分仅为59.2。
笔者用电子邮件向文章作者提了几个问题。其中的一个问题是“人类注释者是什么人?”,由于文章作者在文中提到了“人类注释者承担了构建模因数据集及提供基线人类评分的任务”。Facebook拒绝置评。
第二个问题是“Facebook上的仇恨言论问题的严重程度”。这项工作的出发点是利用人工智能清理社交媒体上的仇恨言论,所以就要知道Facebook是不是需要定期删除仇恨言论,或是到目前为止一共删了多少仇恨言论,这一点很重要。Facebook也拒绝置评。
文章的第一作者Kiela倒是回答了笔者提出的几个重要技术问题。其中一个技术问题是,“这些尖端模型(如Visual BERT)要缩小与人类的差距,还缺什么东西?”
Kiela在给笔者的电子邮件里表示,“假若我们知道缺的是什么,要修补人工智能与人类之间的差距就容易了。总的来说,我们需要在改进多模式的理解和推理方面做工作。”
他表示,“我们知道人工智能基准在推动该领域的发展可以起重要作用。我们的文章,试图推动该研究方向上更多的工作,以及在我们取得的任何进展时提供具体的衡量方式。”
笔者还在电邮里问到“Facebook在利用现有模型处理仇恨言论方面的进展”。Kiela在回邮里表示,Facebook现在用的模型与纯文本BERT模型很接近,是Facebook最近发明的,名为RoBERTa和XLM-R(https://www.zdnet.com/article/facebooks-latest-giant-language-ai-hits-computing-wall-at-500-nvidia-gpus/),两个模型都是非常大的自然语言处理程序。Kiela在电邮里强调,RoBERTa和XLM-R仍然是“单模模型”,因此两个模型都是仅处理文本,不是处理图像的程序,因此,两个模型用于处理多模模型时的性能还存在差距。
笔者还问到一些有关数据集的问题,那个数据集一开始含一百万个示例模因,最终的数据集缩减到10,000个示例。笔者问,为什么是这两个数字?当然,两个数字都似乎是任意的,而且数据集最后只有10,000个样本,似乎很小的数字。
Kiela在电子邮件中告诉笔者,“我们用了许多图像缩减到一万个样本的数据集,这个故事是要说明,我们花了很大的心思设计该数据集。通常,人工智能数据集(尤其是单模人工智能数据集)比这个数据集更好一些,因此我们觉得有必须向人工智能社区解释一下,为什么该数据集相对较小。”
Kiela 表示,“原因是我们用了训练有素的注释者,我们非常谨慎地确保,其他人可以将数据集用于研究目的,而且我们对数据集进行了大量过滤处理,以确保数据集的高质量。”
▲ 图:Facebook示意图:组合多种信号类型进行多模式机器学习的说明。
由于这项研究强调“多模式”方法在深度学习中的重要性,因此笔者最后问了“当今哪种模型最能代表这方面未来的研究方向”。Kiela告诉笔者,朝着ViLBERT及“多模双变换器”方向看。Facebook的Dhruv Batra和Devi Parikh参与了ViLBERT的研发。Kiela和同事研发了多模双变换器,是去年发表的(https://arxiv.org/pdf/1909.02950.pdf)。
ViLBERT和其他多模式人工智能程序的示例代码,可以在Facebook AI的 “ MMF”网站(https://mmf.readthedocs.io/en/latest/)上找到,示例代码内置了各种用PyTorch实现的功能。
从这里开始将如何进一步发展,取决于业界的科学家是否觉得Facebook挑战有其价值,以及对应的数据集是否足以为引导新方法的开发提高基准。
Facebook的想法倒是对到点子上,从总体上解决仇恨言论问题需要自动化,原因是,靠人类构建的数据集本身无法从总体上解决仇恨言论问题。
正如Kiela和同事所说的那样,“靠人类检查每个数据点,无法应付恶意内容的处理。”


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

从技术乌托邦到问题显微镜,AI for Good正在落到实处

北沟村的幸福蝶变:一场时间与技术的乡村交响

DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮

阿里云李飞飞:将大模型,装进数据库里
