 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
AI芯片领域的角逐才刚刚开始

新型架构能够挖掘深度学习的巨大潜力。然而,到目前为止,只有一款AI芯片是完全符合描述和基准测试的,它就是谷歌的TPU。即便如此,这一领域仍然正在蓬勃发展,相关的技术也开始逐渐明朗,比如模拟计算、新兴内存和封装技术、以及一系列专门用于处理神经网络的技术等等。对此,比利时鲁汶大学Marian Verhelst教授表示:
“这个领域涉及范围很广,包括每个层面的研究。”Verhelst教授专门研究探索二元精密格式的芯片。她说,模拟计算很有用,特别是3到8位格式的模拟计算。
NVIDIA首席科学家、资深处理器研究员Bill Dally表示:“NVIDIA有多个和深度学习模拟计算相关的研究项目,但是到目前为止,还没有一个项目可以转化为产品。”他补充说,有一些项目是需要数学神经网络的,生成的结果并不适合用于进行模拟。
“过去那些被否定了的CPU新想法都被重新拿出来进行探索,例如模拟计算、内存处理器、晶圆级集成,”资深计算机研究员David Patterson这样表示,他现在在谷歌工作。“我迫不及待地想看看这些激进的想法是否奏效。”
“两三年前,每个优秀的计算机架构师都会说——'我可以做到100倍速’。正因如此,我们看到大量解决方案已经出现,并且提供了各种功能上的改进,不断逼近当前技术的极限。” Chris Rowen表示,他曾经是MIPS和Tensilica公司的联合创始人,现在又创建了一家人工智能软件公司BabbleLabs。
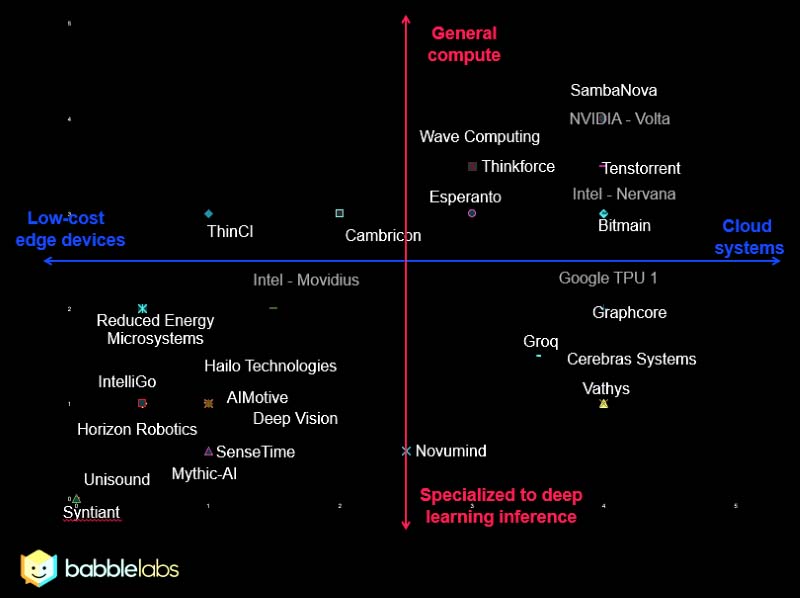
▲ 一张图纵览硅谷的这20多家AI芯片公司(来源:Chris Rowen,BabbleLabs)
>>> AI基准测试遭遇初创公司冷落
处理器设计的复兴给人们带来的一大挫折就是漫长的等待。
去年5月,百度和谷歌公布了MLPerf基准,以一种公平的方式来衡量“几十家”初创公司开发的芯片。该项目负责人Patterson表示:“结果有点令人失望,没有一家初创公司提交第一个迭代的结果。”
“也许他们有战略方面的考虑。但又不禁让人怀疑,他们是不是在开发芯片的过程中遇到了问题,还是芯片性能没有达到他们的预期,又或者是他们的软件不够成熟,无法很好地运行这些基准测试?”
这个训练基准测试采用了ResNet-50,第一个测试结果显示,谷歌TPUv3在从8个芯片扩展到256个芯片的过程中,性能扩展几乎可以达到100%,相比之下,NVIDIA Volta在从8个芯片扩展到640个芯片的过程中,性能扩展了大约27%。
Patterson解释说,TPU之所以占据优势,是因为它可以作为多处理器在自己的网络上运行。相比之下,NVIDIA Volta则是运行在x86集群上的。
Patterson希望未来MLPerf之于AI加速器就像Spec之于CPU。第二批训练结果预计将在今年晚些时候公布。针对数据中心和边缘推理工作的MLPerf基准测试也将在今年首次亮相。
与此同时,也有研究人员警告称,AI芯片行业过于关注峰值性能。“我们认为峰值性能没有什么用,因为峰值性能没有考虑到效率上的差异,”帝国理工学院Erwei Wang博士这样表示,最近他和同事共同撰写了一份关于人工智能加速器的研究报告。他指出,“人们应该公布的是标准数据集和基准测试的持续性能结果,以便更好地对比不同的架构。”
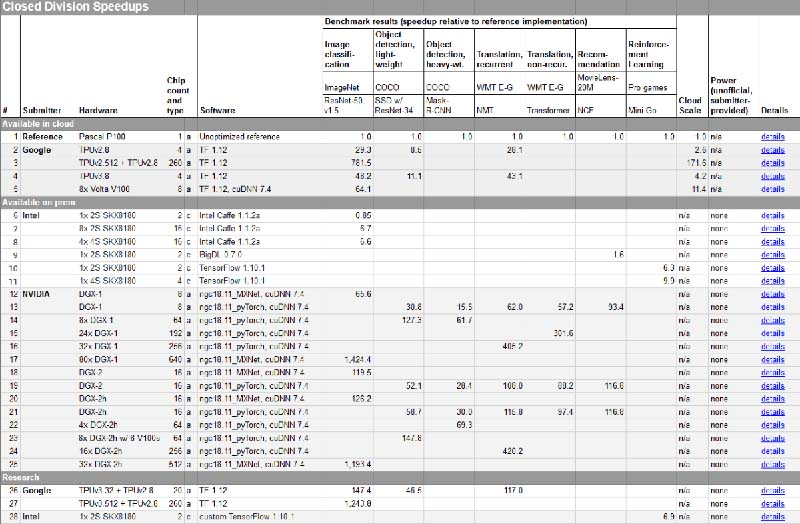
▲MLPerf在12月发布的初步结果采样(有关详细信息请参阅mlperf.org/results。)
>>> 分析师:格局尚不明朗
有分析师抱怨说,包括Graphcore和Wave Computing等在内的知名初创公司到目前为止都没能提供性能数据。唯一的例外是Habana Labs。
The Linley Group分析师Linley Gwennap表示,该初创公司“似乎有一些真实的数据,在白皮书中详细说明其性能是NVIDIA GPU的3到5倍......但他们最初关注的是推理任务,而非训练。”
对此,Moor Insights&Strategy分析师Karl Freund也指出,目前来自初创公司的性能数据确实“少得可怜”。
其中,Habana只是在采样阶段,Wave宣称已有客户采用,Graphcore表示会在4月之前出货芯片产品,Groq可能会在4月北京举行的一个活动上第一次亮相,其他初创公司则可能会于9月在旧金山举行的一次活动上发布产品。
有几家中国初创公司——例如Cambricon和Horizon Robotics,让我们看到了一些希望,这些公司先于美国的同类企业进入市场,专注于人工智能推理领域。
Freund表示:“由于目前在推理领域还没有巨头出现,所以会掀起一股淘金热,但我不知道是否有初创公司能够在训练领域向NVIDIA GPU发起挑战,因为只是在一个产品周期内你无法扭转竞争形势,企业需要可持续的领先地位。”
他说:“唯一一个真正在训练领域站稳脚跟的是英特尔,英特尔已经推出了Nervana芯片,他们正在等待合适的时机,因为如果只是有一堆MAC和降低了的精度,立刻会被NVIDIA秒杀。他们需要解决内存带宽和扩展问题。”
在这场竞赛中,英特尔可以说是多管齐下。英特尔的一位AI软件经理表示,与他工作关系最紧密的,就是至强处理器和前苹果及AMD GPU大师Raja Koduri设计的新GPU。
英特尔最新的Cascade Lake至强处理器中增添了很多新功能,用以加速人工智能。我们预计,英特尔将不再需要GPU或加速器,但也不会放弃与GPU和加速器在性能或效率方面的竞争。
而对于NVIDIA来说,他们正在将最新的12纳米处理器封装到各种工作站、服务器和机架系统中。有人说,NVIDIA在AI训练方面遥遥领先,甚至可以把7纳米产品保留到2020年之后再推出。
除了,NVIDIA之外,许多大厂商也都在基于专有的互连技术、封装技术、编程工具和其他技术构建竞争生态系统。其中,英特尔涉及的技术领域最广泛,包括专有的处理器互连、针对Optane DIMM的内存协议、网络框架、以及新兴的EMIB和Foveros芯片封装。
AMD、Arm、IBM和Xilinx则围绕CCIX(用于极速器的一种缓存一致性互连技术)和GenZ(一种内存链接技术)进行联手。最近,英特尔还发布了一种针对加速器和内存的更开放的处理器互连技术——CXL,但到目前为止,CXL仍然缺少对CCIX和GenZ的第三方支持。

▲AI芯片初创公司列表(来源:Chris Rowen,BabbleLabs)
>>> 数据中心试水DIY芯片
当初创公司争相在服务器系统中为自己的芯片占据一席之地的时候,一些企业却在部署他们自己研发的加速器。
比如:谷歌已经在使用第三代TPU,该版本采用了液体冷却技术,运行平稳;百度去年也宣布推出了自己的首款芯片;亚马逊表示将在今年晚些时候推出首款芯片;Facebook正在组建一支半导体团队;阿里巴巴则在去年收购了一家处理器专业公司。
大多数厂商对其芯片的架构和性能都非常苛刻。百度表示,将发布针对训练和推理任务的不同版本14纳米“昆仑”芯片,可以提供260 TOPS性能,功耗为100 W,其中封装了数千个核心,总内存带宽为512 GB/s。亚马逊方面表示,Inferentia将实现数百TOPS的推理吞吐量,多个芯片聚合在一起可以实现数千TOPS性能。
“很多初创公司都是以面向超大规模数据中心售卖芯片为目标开展业务的,而现在,这可能行不通了,”二级公有云服务商Packet公司首席执行官Zac Smith这样表示。
我们可能永远也看不到云计算巨头设计芯片的拆解细节,但是有一些公开信息描述了很多嵌入块的情况。Linley Group分析师Mike Demler表示,这些嵌入块展现了从改进后的DSP和GPU模块,到使用乘法累加数组,再到数据流体系结构的演变,这种架构将生成的信息从神经网络的一个层面传递到另一个层面。
和三星最新公布的Samsung Exynos中的AI模块一样,很多芯片都转向重度使用网络修剪和量化技术,运行8位和16位操作以优化效率和网络稀疏性。
对网络进行修剪将变得越来越重要。卷积神经网络(CNN)之父Yann LeCun表示,神经网络模型只会越变越大,这就要求性能越来越高。不过他指出,神经网络模型可以被极大程度上进行修剪,特别是考虑到人类大脑最大限度上只被激活了2%。
他在最近一篇针对芯片设计人员的论文中,呼吁开发能够处理极其稀疏网络的芯片。“在大多数情况下,芯片单元都是处于关闭状态的,事件驱动型的硬件具有一定的优势,如此一来,只有激活的单元才会消耗资源。”他这样写道。
“递归神经网络是最稀疏的,因此,使用细粒度修剪也是最有效的。有50%-90%的修剪都是针对CNN的,但是芯片设计人员要面对支持细粒度修剪不规则性和灵活性方面的挑战。”帝国理工学院研究员Erwei Wang这样表示。
减少权重数量和降低精度有助于减少内存需求。Wang说,英特尔的至强芯片和其他很多芯片已经在使用8位整数数据执行推理任务,而FPGA和嵌入式芯片正在向4位甚至二进制精度发展。
这么做是为了让处理操作尽可能靠近内存所在位置,避免片外访问。理想情况下,这意味着能够在寄存器内部或者至少是在缓存内部进行计算。
LeCun甚至在他的论文中设想了一种将内存和处理单元结合起来的可编程寄存器。
“为了让深度学习系统具备推理能力,深度学习系统需要一种短期内存作为情景内存......这样的内存会变得非常普及,而且非常庞大,亟需硬件方面的支持。”他这样写道。

▲根据研究员Erwei Wang及其同事最近对可编程架构的研究调查现实,性能差异是很大的(来源:伦敦帝国理工学院)
>>> MAC单元之外所需的灵活性
如果必须远离芯片,那就把大量请求批量处理成几个较大的请求,这已经是一种很流行的技术。Patterson注意到谷歌最近发表了一篇论文,对于批量操作最理想大小的讨论带来了一些启发。
Patterson表示:“如果你小心操作的话,会在某个区域内得到最理想的加速,然后当你增加批量处理规模的时候,就会发现收益出现递减,然后在很多模型中都表现平平。”
LeCun在论文中警告说:“我们需要新的硬件架构,这些架构在批量处理大小为1的时候可以高效运行。这意味着我们完全不需要依赖于矩阵产品作为最低层级的操作工具。”这一理论无疑是对目前芯片核心的多架构单元的某种终结。
鉴于现在还是深度学习的早期发展阶段,最重要的指导方针是保持灵活性,以及在可编程性和性能之间寻求平衡。
“我们吸取到的教训是,神经网络是持续演化的,你无法对神经网络的维度做出假设,但又希望在各个方面都能保持高效。”负责开发Eyeriss芯片的Vivienne Sze这样表示。
Wang说,在深度学习发展演化的过程中,FPGA将发挥重要的作用,这就要求硬件具备灵活性。他看好Xilinx的Versal ACAP,这是一种FPGA与硬件的混合体。
Wang提出的LUTNet研究探索了如何在无需维护索引的前提下定制查找表,以作为处理细粒度修剪的推理核心。他表示,这将让推理任务所需的芯片减少一半。
这可以说是一个新颖的想法,很多企业已经在这方面进行实践。例如,东芝最近推出了一种ADAS加速器,其94.5平方毫米的芯片中封装了4个Cortex-A53核心,2个Cortex-R4、4个DSP、8个专用加速器模块。
总的来说,对于AI芯片领域,我们还有非常大的想象空间,可以说,好戏才刚刚开始。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

从技术乌托邦到问题显微镜,AI for Good正在落到实处

北沟村的幸福蝶变:一场时间与技术的乡村交响

DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮

阿里云李飞飞:将大模型,装进数据库里
