 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
来自硅谷工程师的Google TensorFlow 教程:开始训练你的第一个RNN吧
自2010年Google的搜索引擎等服务退出中国之后,它也尝试了多种途径重返中国市场,比如推出中国版的Google Play应用商店,却没有取得明显的成功。即便是在目前中国已经成为最大的Android智能手机市场的大势下,也并没有使用Google的服务。
而在7年之际,谷歌再次试图重返中国,这次打出的“王牌”是它的人工智能系统开发框架TensorFlow。
虽然Google的云服务并未入驻中国市场,但中国却有着亚洲增长最快的 TensorFlow开发者社区。目前谷歌正在中国积极推广TensorFlow,希望借此重回庞大的中国AI市场。据了解,已有多名Google美国工程师出席了至少三个在北京和上海举行的 TensorFlow开发者会议,其中两场会议是闭门会议,出席者不允许拍照、记录甚至写博客。
TensorFlow最初由Google Brain团队开发用于Google的研究和生产,2015年11月9日在Apache 2.0开源许可证下发布。自发布至今,已经被下载了超过790万次。
今天,让我们通过硅谷数据工程师Matthew Rubashkin和Matt Mollison所写的TensorFlow RNN教程,来先了解一下如何借助TensorFlow框架训练语音识别的RNN;教程包含了全部代码片段,你可以找到相应的 GitHub 项目,该教程中使用的软件就是源于现有的开源项目的代码。
语音识别:音频与副本(transcriptions)
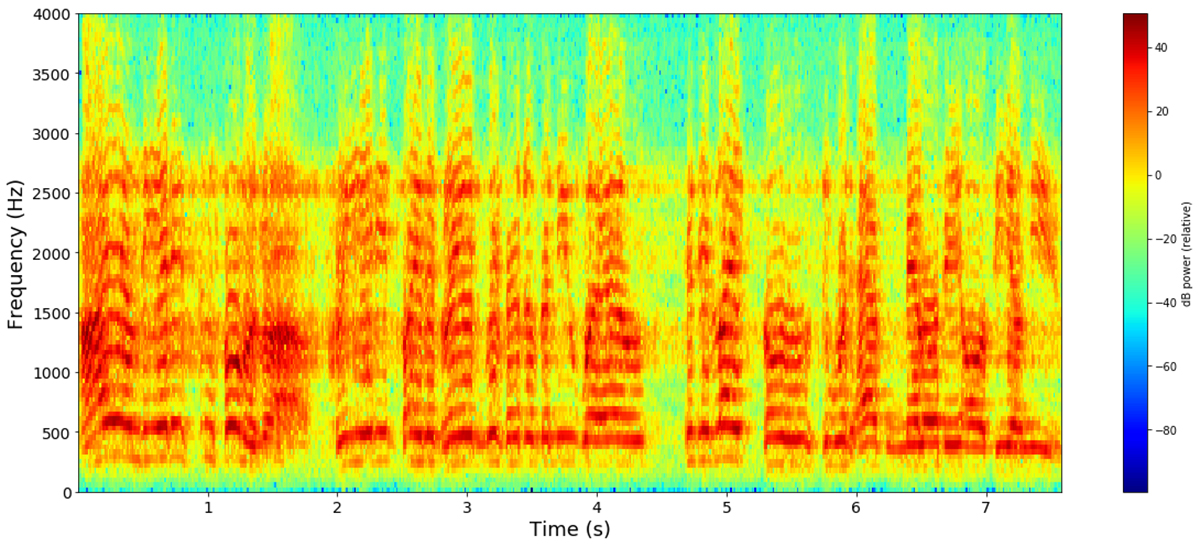
2010年基于语音的方法成为语音识别模型的最新技术,包括发音,声学和语言模型的独立组件。而从过去到现在的语音识别都依赖于使用傅立叶变换公式将声波分解成频率和振幅,并产生如下所示的频谱图:
为传统语音识别流水线而训练隐马尔可夫模型(HMM)的声学模型,需要涉及语音、文本数据,以及一个从单词到音素的字典。HMM是用于顺序数据生成的概率模型,多用于测量字符串中的差异的字符串度量,并且通常使用Levenshtein word error distance来评估。
这些模型可以通过与音素副本对应的语音数据进行简化和精准化,但这是一个非常繁琐的工作。因此,相较于音素级别的副本,词级的副本更可能存在大量的语音数据集。
Connectionist Temporal Classification(CTC)损失函数
当使用神经网络进行语音识别时,我们可以先抛开音素的概念,而使用允许预测字符级副本的基于神经网络的时序分类(CTC)的目标函数。简而言之,CTC能够实现多个序列概率的计算,这里的序列是指语音样本的所有可能的字符级副本的集合。而网络使用目标函数,则可以最大化字符序列的概率(即可以选择可能性最大的副本),并且通过计算预测结果与实际副本之间的误差从而更新训练期间的网络权重。
值得注意的是,CTC损失函数使用的字符级误差与传统语音识别模型中经常使用的Levenshtein word error distance不同。对于字符生成的RNN模型而言,字符和单词之间的误差与在诸如Esperonto和Croatian的语音语言中类似,不同的声音会对应于不同的字符。相反,对于非语音语言(如英语),字符与单词之间的误差就非常不同了。
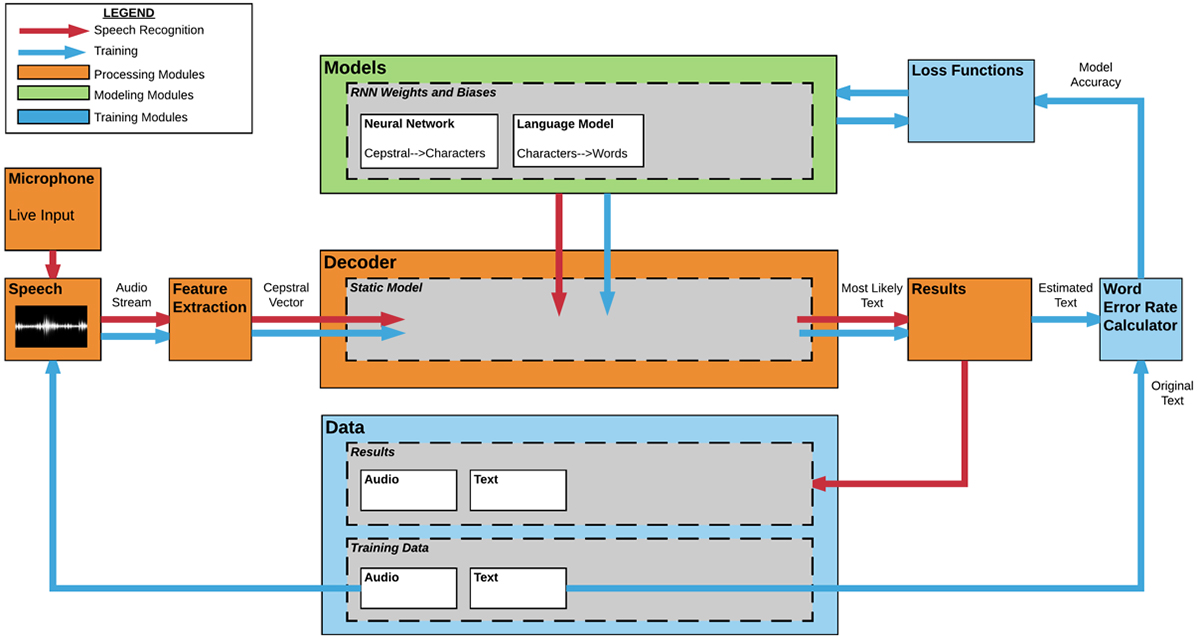
为了进一步利用为传统或深度学习语音识别模型而开发的算法,我们的团队构建了模块化和快速原型的语音识别平台:
数据的重要性
毫无疑问,创建一个将语音转成文本的系统,需要数字音频文件和文字的副本。而由于该模型将适用于解码任何新的语音样本,因此,在系统中供我们进行训练的样本越多,模型的表现也就越好。
对此,我们研究了可免费获取的英语演讲录音,包括了LibriSpeech(1000小时),TED-LIUM(118小时)和VoxForge(130小时)等不同的样本,以供训练使用。
下面的图表展现了这些数据集的信息,包括总时长、采样率和注释:

为了方便地从任何数据源中访问数据,我们以扁平的格式存储所有数据,如.wav格式和.txt格式。
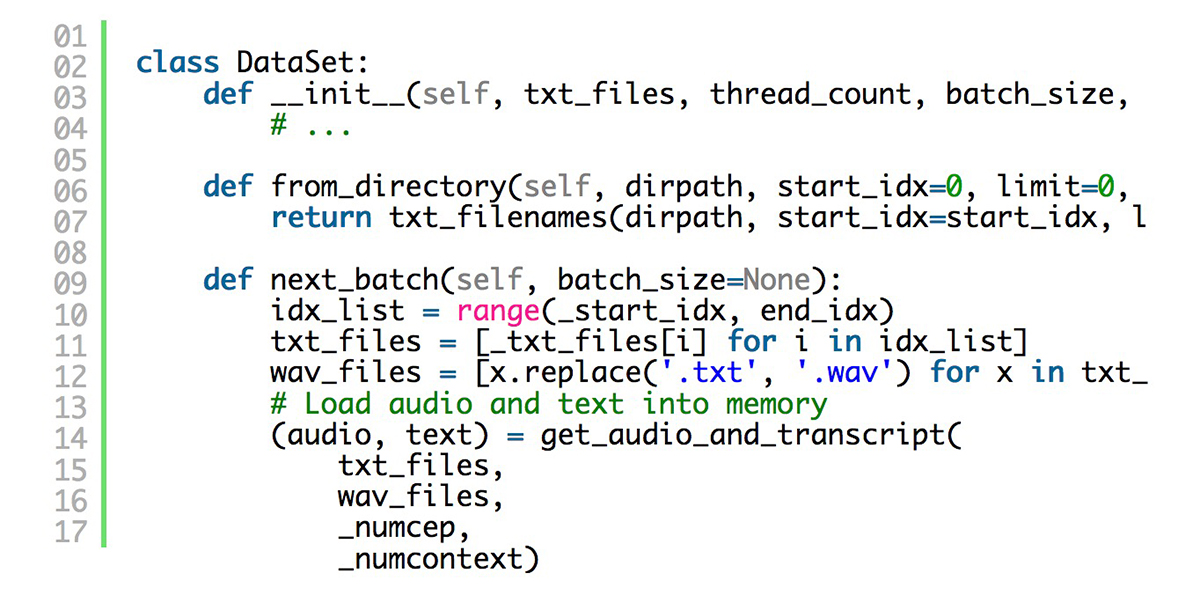
举个例子,你可以在我们的GitHub repo中找到Librispeech训练数据集中的“211-122425-0059”数据所对应的文件,例如211-122425-0059.wav和211-122425-0059.txt。这些数据文件名使用数据集对象类加载到TensorFlow图中,这有助于TensorFlow有效地加载、预处理数据,并将各批数据从CPU加载到GPU内存中。以下是数据集对象中数据字段的示例:
特征表征(representation)
为了使机器更好地识别音频数据,数据必须先从时域转换到频域。这里有几种方法可以创建用于提取机器学习特征的音频数据,包括通过任意频率分级(如每100Hz),以及通过使用人耳能够听到的频率波段分级。这种典型的以人为中心的语音数据转换是计算13位或26位不同倒谱特征的梅尔频率倒谱系数(MFCC)的,它可以作为模型的输入。经过转换,数据将被存储在一个频率系数(行)随时间(列)的矩阵中。

由于语音不会孤立地产生,并且没有一对一映射到字符,所以我们可以通过在当前的时间索引之前和之后捕获声音的重叠窗口(10s)上训练网络,从而捕获共同作用的影响(通过影响一个声音影响另一个发音)。
以下是如何获取MFCC功能以及如何创建音频数据的窗口的示例代码:

对于RNN 示例来说,我们使用之前的9个时间片段和之后的9个时间片段,每个窗口总共包括了19个时间点。当倒谱系数为26的情况下,每25毫秒会有494个数据点。而根据数据的采样率,我们建议对于16000Hz使用26个倒谱特征,对8000Hz使用13个倒谱特征。
以下是8,000 Hz数据的加载窗口示例:
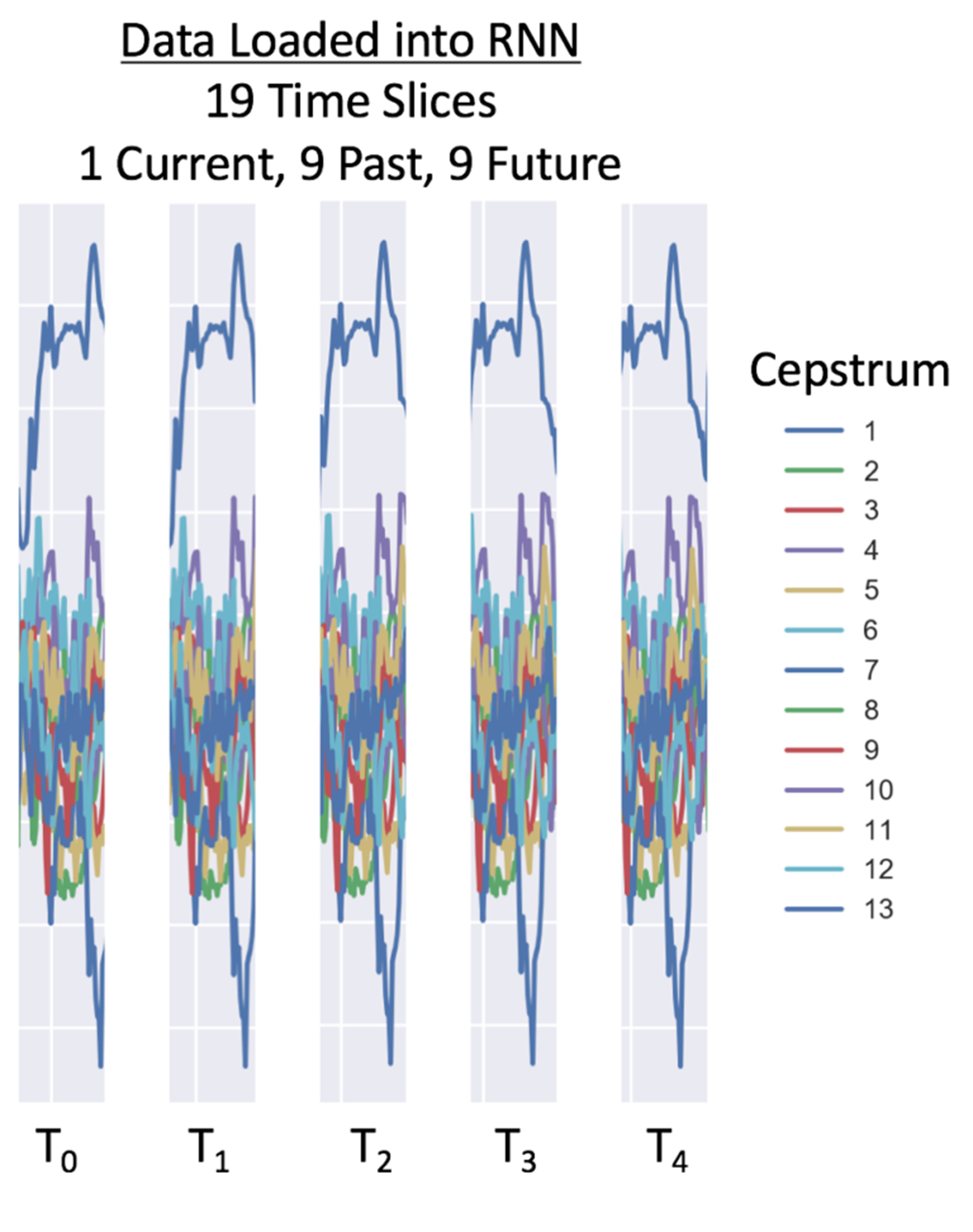
语音的序列性建模
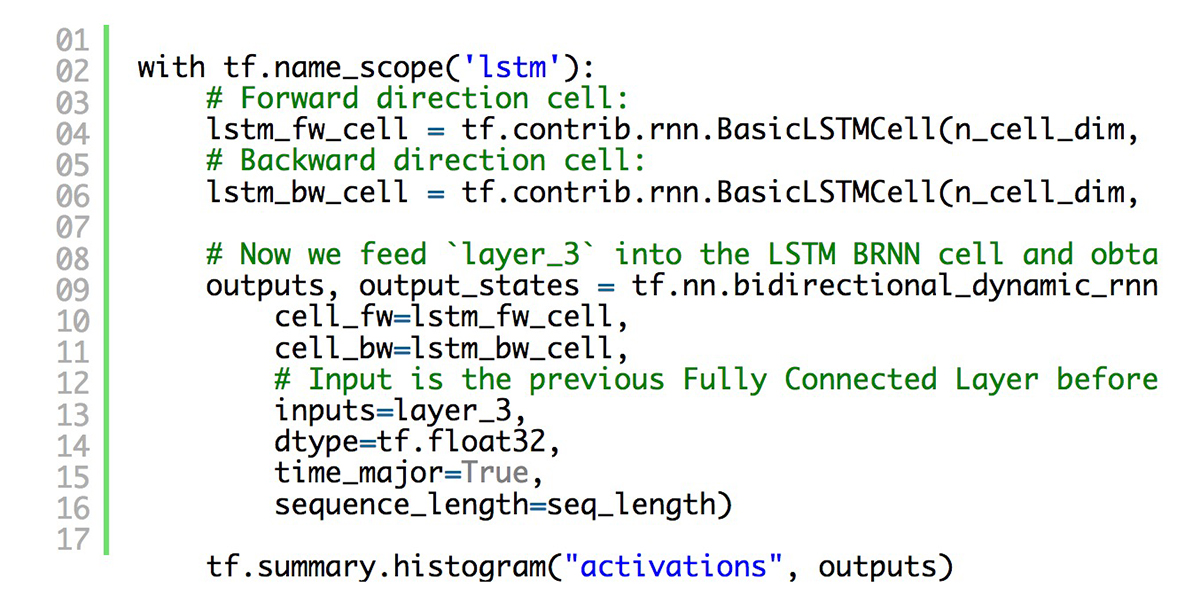
长短期记忆网络(LSTM)层是一种循环神经网络(RNN)架构,可用于对具有长期顺序依赖性的数据进行建模。由于它们从根本上记住了当前时间点的历史信息,而这些信息会影响结果的输出,因此它们对于时间序列数据非常重要。 而也正因这样的时态特征,使得上下文具有了联系性,这对于语音识别非常有效。
以下展示了深度语音启发(DeepSpeech-inspired)的双向神经网络(BiRNN)中 LSTM 层的示例代码:
网络训练与监控
通过使用Tensorflow训练网络,我们花很少的精力就可以实现计算图表的可视化,同时也可以使用TensorBoard从门户网站上进行监视训练、验证以及性能测试。根据Dandelion Mane在2017年Tensorflow发展峰会上做演讲中提到的技巧,我们使用tf.name_scope来增加节点和层名,并将总结写到了文件中。
其结果是自动生成的,并且是可理解的计算图表。以双向神经网络(BiRNN)为例(如下图),数据在左下方到右上方的不同操作间进行传递。为了更清楚地展现,可以为不同的节点做标注,并使用命名空间对节点进行着色。在这个例子中,青色的“fc”盒子对应全连接层,而绿色 的'“b”和“h”盒子分别对应偏移量和权重。
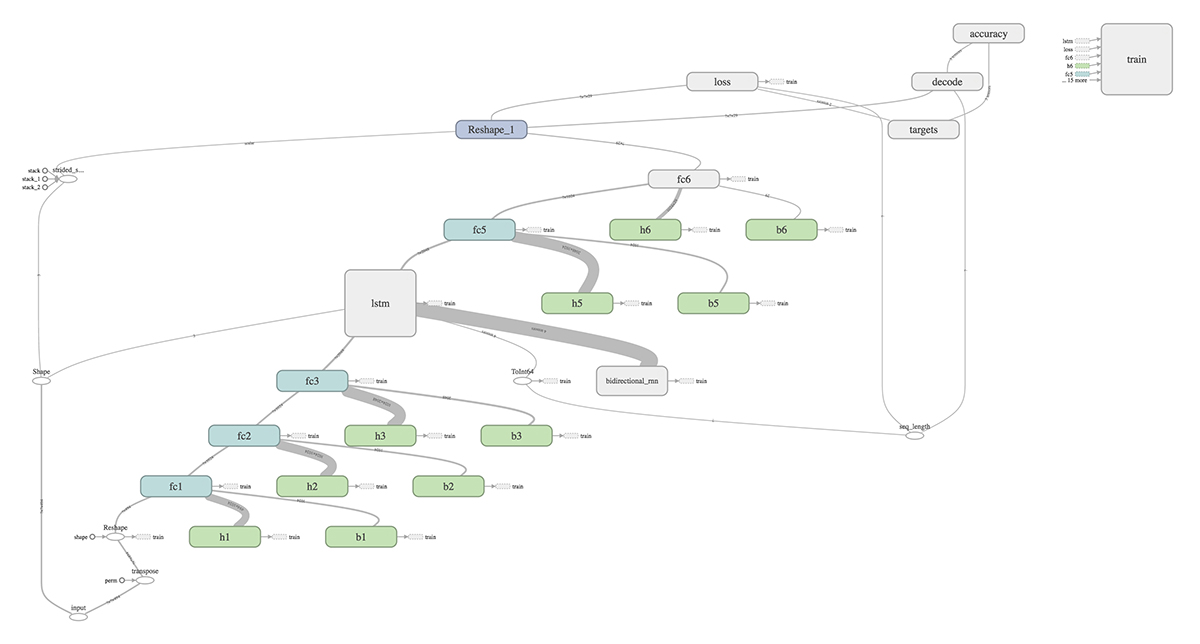
我们使用TensorFlow提供的tf.train.AdamOptimizer来控制学习率。 而AdamOptimizer则通过使用动量(参数的移动平均值)来改善传统梯度下降,从而促进超参数的有效动态调整。此外,我们还可以通过创建标签错误率的摘要标量来跟踪丢失和错误率:

如何改进RNN
现在我们已经建立了一个简单的LSTM RNN网络,那么,如何降低其中的错误率呢?非常幸运的是,对于开源社区而言,许多大公司都已经发布了他们表现最好的语音识别模型的背后的数学模型。早在2016年9月,微软就发布了一篇文章,描述了他们如何在NIST 200交换机数据上将错误率降到6.9%。他们在卷积+递归神经网络之上使用了几种不同的声学和语言模型。
微软团队和其他研究人员在过去4年中所做的几项重大改进包括:
- 在基于RNN的字符之上使用语言模型
- 使用卷积神经网络(CNN)从音频中提取特征
- 利用多个RNN的综合模型
值得注意的是,在过去几十年的传统语音识别模型中率先开发的语言模型,在深度学习语音识别模型中再次被证明是有价值的。

改进来自:A Historical Perspective of Speech Recognition, Xuedong Huang, James Baker, Raj Reddy Communications of the ACM, Vol. 57 No. 1, Pages 94-103, 2014
训练你的第一个RNN
我们提供了一个 GitHub项目(GitHub repository),该项目的脚本提供了一个用RNNs和CTC损失函数(在TensorFlow中),训练端到端语音识别系统的简单易行执行方案。GitHub库中包含了来自LibriVox 语料库(LibriVox corpus )示例数据,这些数据被分为如下几个文件夹:
- 训练:train-clean-100-wav(5个示例)
- 测试:test-clean-wav(2个示例)
- Dev: dev-clean-wav (2个示例)
当训练这几个示例时,你会很快注意到训练数据会过度拟合(overfit),这使得错词率(WER)约为0%,而测试集和Dev数据集的WER大约能达到85%。测试错误率之所以不是100%,是因为机器需要在29个可能的字符间做选择(a-z,省略号,空格键,空白),但网络将很快学习到:
- 某些字符(e,a,空格键,r, s, t)更常见
- 辅音-元音-辅音在英语中是一种模式
- MFCC输入声音特征增加的信号幅度对应着字符a - z
在GitHub库中使用默认设置做训练,运行结果如下图所示:
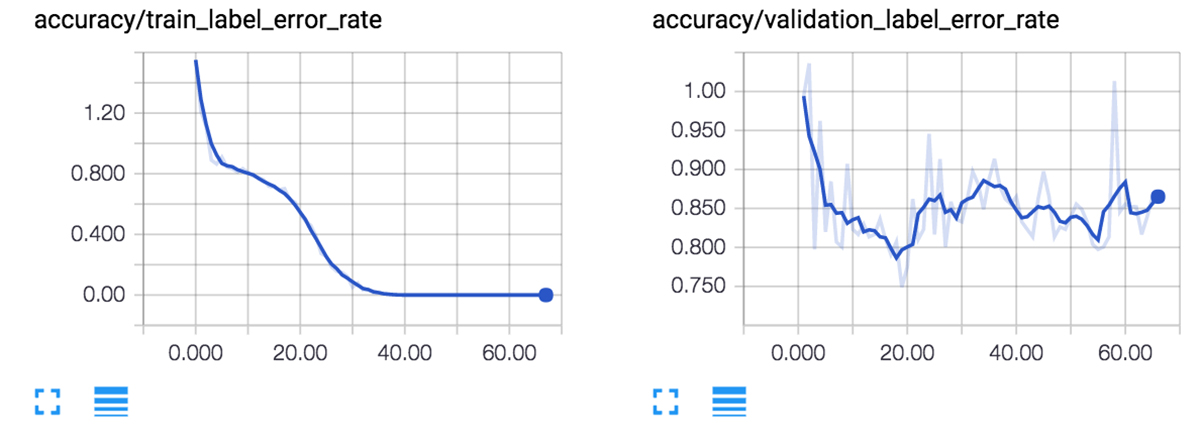
如果你想训练一个高性能的模型,还可以在文件夹中添加额外的.wav和.txt文件,或者创建一个新的文件夹,并用文件夹位置更新`configs / neural_network.ini`。需要注意的是,即使使用强大的GPU,在仅仅几百个小时的音频上做处理和训练也需要非常大的计算能力。
| 编译:科技行者
| 来源:SVDS


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

从技术乌托邦到问题显微镜,AI for Good正在落到实处

北沟村的幸福蝶变:一场时间与技术的乡村交响

DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮

阿里云李飞飞:将大模型,装进数据库里
