 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
从AIDC到AIPC,英特尔如何为AI原生提供算力新答案?
作者|周雅
狂奔了将近一年后,大模型的风终究是吹到了更实在的应用落地,这对于几乎所有AI创业者来说,是机会也是挑战。
要知道,大模型不是平地起高楼的新物种,它是在过去算力不断迭代、数据量不断扩充的基础上,涌现的一种技术产物。所以对大部分创业者来说,即使自己不从头开发基础大模型,但如果为了模型微调及增加RAG知识库,为产品增加垂类知识;优化用户交互体验;提高Token输出效率,一定的算力仍是必须。
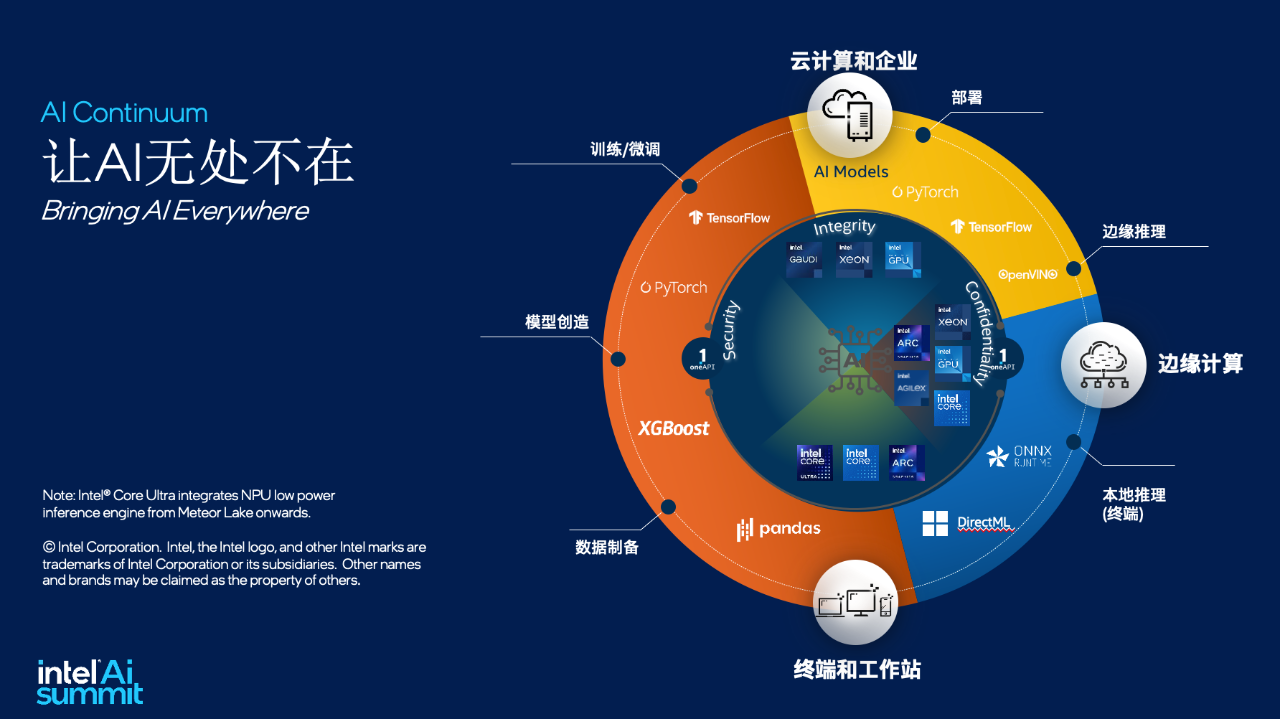
正如近期由英特尔和至顶科技组织的 AI Summit·PEC AI新势力专场活动上,来自产学研的参会嘉宾所达成的一致共识是,智能场景无处不在,来自“端、边、云”的智能算力也无处不在。
面向AI带来的智算时代,多年来一直根植于算力生态的英特尔,打出了“让AI无处不在(Bring AI Everywhere)”的口号,从硬件到软件到生态,全面拥抱AI,赋能AI创业者。

从云原生到AI原生:先解成本难题
如果说,过去的互联网或移动互联网创业企业,伴随云计算的发展,从「上云」发展到「云原生」;那么在当下的AI时代,数智化不断迭代升级的过程中,一批创业企业已经开始「AI原生」,甚至是一出生就长在大模型上。
根据Gartner预测,到2026年,超过80%的企业将在生产环境中采用生成式AI的API、模型,并部署启用生成式AI应用——这些都指向了AI原生应用的机遇。
但是问题来了,AI原生企业在选择算力方案时会面临一系列的算力问题。在这次 AI Summit上,从业者一致认为,算力挑战是普遍现象,「算力成本」是主要门槛。上海人工智能实验室、训练框架与编译技术负责人裴芝林在活动上提及了3个算力成本问题:
第一,硬件选型成本,如何选择和自己业务匹配的芯片,以最小的成本服务用户;
第二,软件在应用层面的研发投入成本,如何打通软件开发到应用落地的最后一步;
第三,如何发挥软件+硬件的成本效率,达到易用性。
为此,英特尔中国软件技术合作事业部高级总监刘斌总结说道,这些企业需要以下解决方案,即:非单一GPU来源的“更多可靠选择;以适用既有软件资产和网络条件的“稳定可持续”;在保持较低基础架构成本的前提下的“可扩展”;可以解决多种业务挑战的“效益最大化”。
不过,方案再好,也需要在交付环节同样“靠谱”。对此,英特尔也给出了全方位的应对之策。
策略之一,根据业务场景需求,提供成本更优的算力方案。
如今AI大模型的训练和推理动辄需要千卡乃至万卡,而一张GPU卡动辄几万、十几万乃至二十几万,对于AI原生企业来说,如果盲目选择GPU服务器算力,将会面对巨大的试错成本。
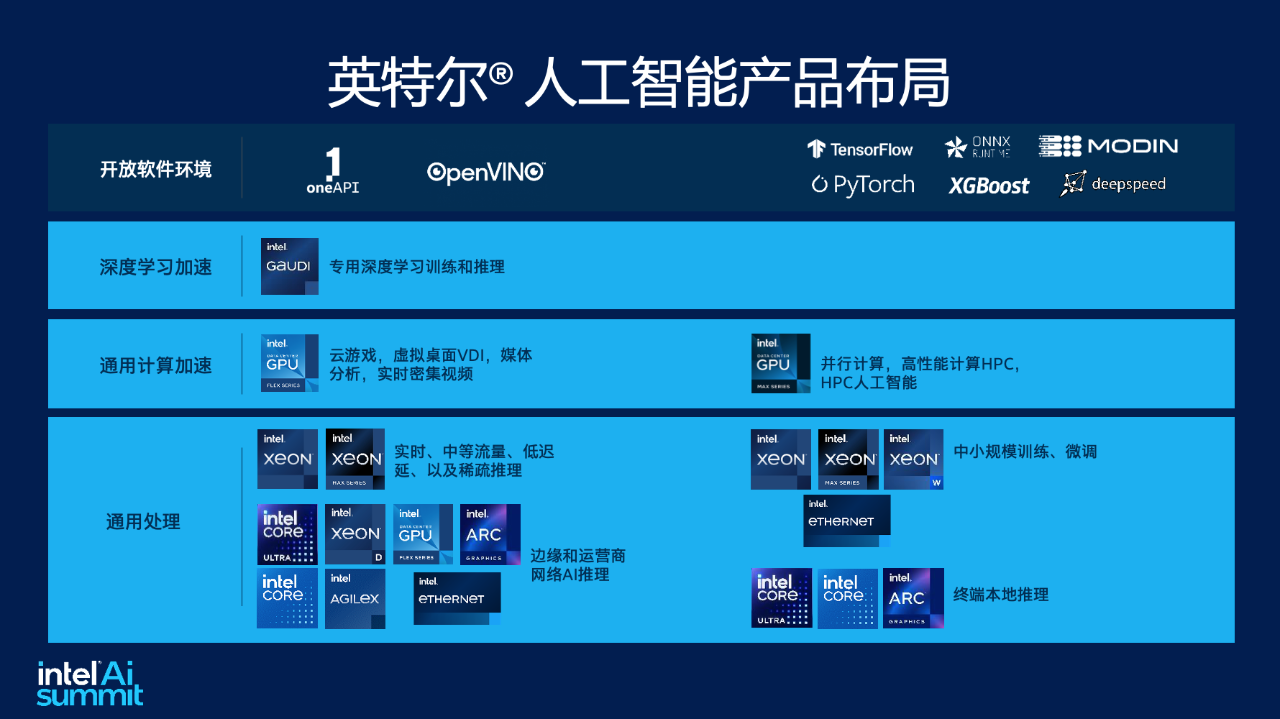
英特尔提供了堆GPU之外的另一个选择——CPU。
为了满足不同工作负载的需求,最新登场的至强® 6采用了两种微架构——E-core(能效核)和P-core(性能核)。E-core的功耗更低,适用于微服务等传统后端应用场景,而P-core拥有高达128个内核和504MB的超大L3缓存,可为AI、数据分析、科学计算等计算密集型业务提供卓越的性能支持。
在9月26日英特尔刚刚举办的至强® 6性能核处理器发布会上,英特尔数据中心与人工智能集团副总裁兼中国区总经理陈葆立介绍:“英特尔在设计处理器时,会分别设计两个单元——计算单元和I/O单元。”二者解耦的分离式模块化设计,可灵活组合不同数量的计算单元,实现核心数量的扩展及内存和I/O的同步强化,保证更优的整体性能和能效。

至强® 除了能兼顾通用计算、兼顾AI推理之外,还能作为机头处理器与AI加速器或GPU协作,面向AI企业、AI创造者多元化地推出算力组合,提供端到端方案,解决AI原生企业面临的算力成本问题。
在云端算力方面,英特尔提供了至强® (内置AI加速器)和Gaudi® 组合的方案,充分利用企业既有IT基础设施的同时,提供了更具性价比的AI落地方案。
以英特尔®Gaudi® 为例,它是一个AI专用处理器,专为生成式AI和大模型而生。作为一款完全可编程的高性能AI加速器,Gaudi®融合了多种技术创新,具有高内存带宽/容量,还拥有较好的可扩展性,能够支持轻松高效的网络功能。Gaudi®可以支持绝大多数大模型,拥有较成熟的软件生态,英特尔提供的软件套件也会帮助AI模型的开发和部署,从而让企业接入的时候更容易。
随着AI算力向桌面端的渗透,在边缘端和端侧的算力方面,英特尔同样有酷睿™ Ultra和ARC™ 提供全方位的硬件平台加持。
其中,酷睿™ Ultra是英特尔客户端处理器路线图的一个转折点。该款处理器通过集成英特尔® 锐炫™ 显卡带来了独立显卡级别的性能。而且它还配备了英特尔首款集成的神经网络处理器(NPU),用于在PC上带来高能效的AI加速和本地推理体验。
“本质上,这是一个算力和成本的选择。针对大模型的推理,智算中心的建设,可以优先看至强处理器和Gaudi® AI加速器;而针对端侧,酷睿™ Ultra则提供了更佳选择,它集成了GPU+NPU的能力,算力最高可达120TPOS。”刘斌补充说道。
显然,无论是在数据中心、云端、还AI PC在内的端侧,英特尔都能提供成本更优的算力方案。
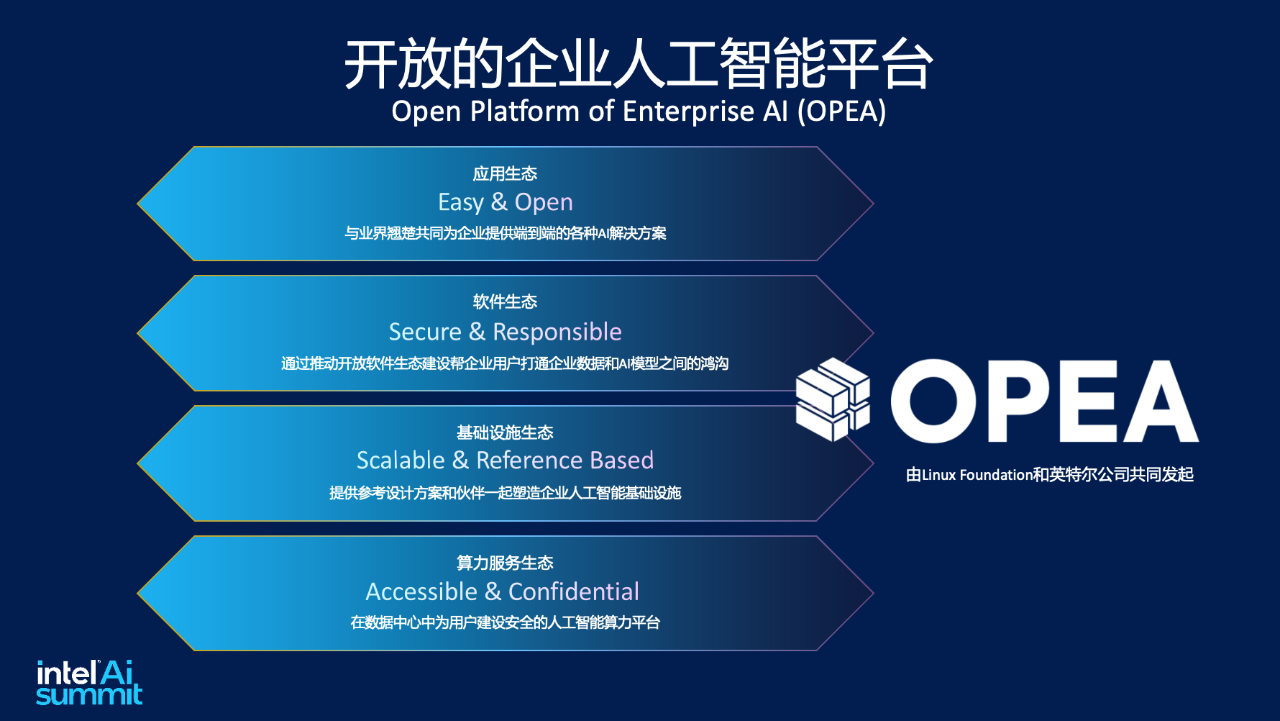
策略二,打造开放共赢的企业AI平台。
当然,英特尔所做的,并不止于降本扶持。今年6月,英特尔联合行业领先企业最新推出了“企业AI开放平台,Open Platform of Enterprise AI (OPEA)”。该平台集成了API参考代码、异构硬件等高效技术支持,并提供参考工作流程、规范等多种服务,这为软硬件提供商等不同的生态角色提供了丰富的价值,如降低研发成本、多样化软硬件供应链、聚焦模块创新、助力系统级交付、实现便捷灵活部署、加速产品推向市场和迭代等。
目前,OPEA已成为Linux Foundation AI & Data旗下的重要开源项目,以期凝聚行业动能,共同减少生成式AI生态系统的复杂性,帮助企业通过生成式AI更快、更轻松地从自有数据中解锁价值,促使企业AI解决方案能够更快捷地落地。
“无论是基于云原生的架构,还是AI原生的架构,OPEA都是最开放的框架,它本身没有任何的商业含义,它的初衷是用一个更纯粹的方式让大家互惠互通。”刘斌强调。
技术支持,联合市场推广,加速业务增长
为了帮助企业更好的利用算力资源,英特尔一方面提供CPU指令集调用,OS kernel层开发,底层资源库的调用等技术支持,另一方面提供多种工具开发包,套件,函数库,等等,用于帮助完成软件优化和研发。
当合作伙伴的产品或方案进入市场,英特尔市场部会提供营销支持,通过案例推广、产品联合发布、媒体宣传、线下需求对接会等多种方式进行宣传推广,帮助合作伙伴的产品打开市场,获取商机。
诚然,从云原生、到AI原生的背后,也是从基础设施的优化、到应用层面智能的转变。其中,云原生提供了强大的基础设施支持,为AI原生应用的开发和运行提供了基础。而AI原生则在此基础上,通过集成大模型、生成式AI等技术,使得应用程序能够提供更加智能化的服务和体验。
新算力 重新定义新硬件
算力无所不在,不仅在创造原生应用,也在重新定义硬件,AIPC就是一个例子。
如同云计算在逐渐由云端主导过渡到边云协同,另外一方面,AI算力也将从数据中心逐渐向端侧延伸。在这当中,AIPC是其中的重要一环。此前英特尔预言,到2028年80%的PC将成为AI PC。
可见,PC正在AI时代重新焕发光彩。AIDC(AI算力中心)和AIPC(AI个人电脑),二者也相得益彰。
在云端,算力成本将随着用户量的增加而变得更加显性,AIPC有机会把一些不需要大量计算、对实时性要求不高、但需要及时反馈的日常需求用端侧的算力来解决,数据不出端,既保证了数据安全,又极大地降低企业部署的成本。
举例而言,假设一家涉及设计IP的企业,每个员工每天要向云端模型密集提问,为企业增加了订阅或者Token费用的同时,隐私安全也是绕不过的门槛。但如果这家企业的每个员工升级了AI PC,短期看成本或许会增加,但长期看其实降低了成本,优化了场景适配。
新生态,赋能新应用
无论是云原生,还是AI原生,关键都在于应用场景。因为只有当技术“能用”,才能发挥它真正的价值,这也是为什么创业公司永远在追求PMF(产品市场验证)的原因。
软积木创始人、微软MVP黄海峰在此活动上指出,“除了要把算力平台运行起来,更重要的还是转换成生产力,给社会、企业带来价值,要通过AI的应用去解决,通过平台去解决。”
对此,英特尔也一直在赋能软件生态建设。在AI产品布局的最上层“应用层”,英特尔提供了丰富的软件工具来加速AI发展,比如英特尔® oneAPI AI Analytics 工具套件、BigDL 和 OpenVINO™ 工具套件等,不仅能为开发者提供强大的AI开发和推理能力,也为跨英特尔硬件的异构执行提供支持。
值得一提的是,这些工具中的大部分都是开源软件。作为Linux Kernel、Kubernetes、云原生等领域的主要贡献者,英特尔不止一次对外强调,对于开源软件生态的建设与重视,通过与生态合作伙伴的开放的共赢的关系,为企业提供最好的解决方案。
当然,为了挖掘AIPC的更多应用场景,除了给开发者提供工具,英特尔还为这些开发者提供土壤,鼓励创新。
从去年12月起,英特尔与联想开启了英特尔人工智能创新应用大赛,为AI时代开发者提供挥洒创意、展示成功的示范平台,让AI惠及更多的终端用户。
而在今年3月,英特尔还推出了“AI PC开发者计划”,专门为软件开发者和独立软件供应商设计,以求为其提供流畅的开发体验,帮助开发者更容易地实现新型AI技术的大规模应用。

总结而言,英特尔持续在“用CPU加速AI”,而且除了CPU之外,英特尔也在GPU、AI专用加速芯片上不断研发和创新,以其全栈算力为客户提供更具性价比的方案、为创建绿色数据中心、开发软件和工具提供源源不断的支持。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

5G变现困境如何破?爱立信认为“新质网络”是关键
全球5G发展已进入瓶颈期,由于缺乏杀手级应用,5G的变现能力未达预期,运营商迫切需要探索新的商业模式与变现方式。




5G变现困境如何破?爱立信认为“新质网络”是关键

液晶显示电视什么值得买 这里有5条来自BOE(京东方)的“真像”

荣耀MagicOS、YOYO智能体和“忒修斯之船”

高通史诗级骁龙上线,安蒙说时代变了,AI First的未来,是所有App都是“王牌应用”

周雅
主编
