 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
人工智能与深度学习技术16大回顾,承包你一年的知识点
CNET科技行者 1月5日 北京消息(编译/黄当当):
- 强化学习在游戏中全面压制人类选手 -
2017年的第一件大事无疑当数AlphaGo。这套强化学习方案击败了全球最出色的围棋选手。由于拥有巨大的搜索空间,围棋一直是机器学习技术难以攻克的重要挑战所在,AlphaGo的出现则带来了巨大的惊喜!
- AlphaGo研究论文
https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
AlphaGo的初始版本利用来自人类专家的训练数据作为指导,并通过自我推衍以及蒙特卡洛树搜索作出进一步改进。在不久之后,AlphaGo Zero在此基础之上更进一步,其能够学会如何从零开始进行围棋对弈,且无需任何人工训练数据。此外,它还轻松击败了AlphaGo的初始版本。
- 研究论文
https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ

在2017年底,我们再度迎来AlphaGo Zero的全新算法AlphaZero,其不仅在围棋领域无可匹敌,同时亦快速称霸国际象棋与日本将棋。有趣的是,这些程序甚至令最具经验的职业棋手们敬佩不已,并开始从AlphaGo当中学习以调整自己的竞技风格。为了简化这种学习过程,DeepMind小组还发布了专门的AlphaGo Teach工具。
https://arxiv.org/abs/1712.01815
- AlphaGo Teach
https://alphagoteach.deepmind.com/
不过围棋绝不是我们在机器学习领域取得显著成就的唯一领域。来自卡耐基梅隆大学的研究人员们开发出的 Libratus 系统在一场为期20天的德州扑克锦标赛当中成功击败了各位顶级选手。而在此之前,由查尔斯大学、捷克技术大学以及艾伯塔大学研究人员们开发的DeepStack系统则成为首款能够在德州扑克领域压倒人类选手的成果。需要注意的是,这两套系统都只能进行单人扑克竞赛,即一对一比赛——这类情况要比多人扑克简单得多。不过相信多方扑克支持能力将会在2018年内逐步得到实现。
- Libratus论文:
http://science.sciencemag.org/content/early/2017/12/15/science.aao1733.full
强化学习的下一个发展领域似乎将面向更为复杂的多人游戏——其中当然也包括多人扑克比赛。DeepMind小组目前正在积极研究《星际争霸2》并已经发布研究环境;OpenAI则在一对一的《Dota 2》游戏当中初步获得成功,预计将能够在不久的未来实际参与五对五正式游戏比赛。
- 星际争霸2研究环境
https://deepmind.com/blog/deepmind-and-blizzard-open-starcraft-ii-ai-research-environment
- Open AI Dota2
https://blog.openai.com/dota-2
- 进化算法再度回归 -
对于监督学习,基于梯度的反向传播算法已经获得了非常好的效果,而且这一点很可能在未来一段时间内继续得到保持。然而在强化学习层面,进化策略(简称ES)则似乎正在东山再起。由于数据通常不符合iid原则(即独立且分布相同),因此错误信号将更加稀疏; 而且由于需要进行探索,所以其它非基于梯度型算法往往效果更为理想。另外,进化算法将能够以线性方式扩展至数千台设备当中,从而实现极快的并行熟练工。其不需要昂贵的GPU资源,而可通过大量(通常为数百乃至数千)低成本CPU实现训练。
2017年早些时候,来自OpenAI的研究人员们证明,进化策略可以实现与标准强化学习算法(例如Deep Q-Learning)相媲美的处理效能。而到2017年底,Uber的一个团队发布了一篇博文与一组五篇研究论文,旨在进一步展示遗传算法与新颖性检索的潜力。利用一种非常简单的遗传算法,且无需任何梯度信息,其算法即可学会如何游玩多种不同的雅达利游戏。其最终得分达到10500,相比之下DQN、AC3以及ES等方法的得分则统统低于1000分。
- 相关论文:
https://eng.uber.com/deep-neuroevolution
2018年,我们很可能看到这方面出现更多研发成果。
- WaveNets、CNN以及关注机制 -
谷歌的Tacotron 2文本到语音转换系统能够生成令人印象深刻的音频样本,其基于WaveNet——一种亦被部署于谷歌助手当中的自动回归模型,且在过去一年中实现了巨大的速度提升。WaveNet此前亦被应用于机器翻译领域,能够显著加快回归架构的训练速度。
单从回归架构的角度来看,投入大量时间对其加以训练似乎成为这一机器学习子领域当中的主流趋势。不过在Attention Is All You Need(论文)的帮助下,研究人员们得以彻底摆脱回归与卷积等方法,转而利用一套更为复杂的关注机制在更短的训练时间之内获得最为出色的训练成果。
- 谷歌Tacotron 2
https://research.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
https://google.github.io/tacotron/publications/tacotron2/index.html
- WaveNet
https://deepmind.com/blog/wavenet-generative-model-raw-audio/ https://deepmind.com/blog/high-fidelity-speech-synthesis-wavenet/
- Attention Is All You Need论文
https://arxiv.org/abs/1706.03762
- 深度学习框架的爆发元年 -
如果要用一句话来总结整个2017年,那么我会将其称为框架爆发的元年。Facebook凭借着PyTorch首开先河,由于其动态图形结构与Chainer非常类似,因此PyTorch得到了自然语言处理研究人员们的高度支持——这主要是由于他们经常需要处理动态且复杂的结构,而这些结构往往很难在静态框架(例如TensorFlow)当中进行声明。
当然,TensorFlow在2017年同样获得了辉煌的成功。TensorFlow 1.0于2017年2月发布,其中包含一个稳定且向下兼容的API。目前TensorFlow的最新版本为1.4.1。除了主框架之外,TensorFlow还拥有多种配套库,包括用于动态计算图的TensorFlow Fold、用于数据输入管道的TensorFlow Transform以及DeepMind开发的高级Sonnet库。TensorFlow团队亦公布了一套新的迫切执行(eager execution)模式,其工作方式类似于PyTorch当中的动态计算图。
相关资料:
- TensorFlow 1.0
https://github.com/tensorflow/tensorflow/releases/tag/v1.0.0
- TensorFlow Fold
https://research.googleblog.com/2017/02/announcing-tensorflow-fold-deep.html
- TensorFlow Transform
https://research.googleblog.com/2017/02/preprocessing-for-machine-learning-with.html
https://deepmind.com/blog/open-sourcing-sonnet/
- eager execution
https://research.googleblog.com/2017/10/eager-execution-imperative-define-by.html
除了谷歌与Facebook之外,众多其它企业亦加入到这波机器学习框架的开发大潮当中:
- 苹果公布其CoreML移动机器学习库。
- Uber研发团队发布Pyro,一种深度概率编程语言。
- Amazon发布Gluon,立足MXNet的高级API。
- Uber发布了其内部Michelangelo机器学习基础设施平台的更多细节信息。
面对框架数量爆发式增长的现状,Facebook与微软则联合公布了ONNX开放格式,用于在不同框架之间共享深度学习模型。举例来说,大家可以在一种框架当中训练自己的模型,并随后立足其它框架将其投入实际生产。
除了通用型深度学习框架之外,我们还看到大量强化学习框架正在发展当中,具体包括:
https://blog.openai.com/roboschool
- OpenAI Baselines 是一套高质量强化学习算法集合。
https://github.com/openai/baselines
https://github.com/tensorflow/agents
- Unity ML Agents 允许研究人员与开发人员利用Unity Editor创建游戏与模拟,并利用强化学习完成训练。
https://github.com/Unity-Technologies/ml-agents
- Nervana Coach 允许用户利用最先进的强化学习算法进行实验。
http://coach.nervanasys.com/
- Facebook的ELF 平台可用于游戏研究。
https://code.facebook.com/posts/132985767285406/introducing-elf-an-extensive-lightweight-and-flexible-platform-for-game-research/
- 。
https://github.com/deepmind/pycolab
- Geek.ai MAgent 是一套用于进行多代理强化学习的研究平台。
https://github.com/geek-ai/MAgent
为了进一步简化深度学习的上手门槛,面向Web的框架方案也应运而生——其中包括谷歌公司的deeplearn.js以及MIL WebDNN执行框架。
不过作为一款非常流行的框架,Theano已经走向其生命的终点。根据Theano项目往来邮件列表中的一份声明,开发者们决定将1.0作为该项目的最终版本。
- 学习资源 -
随着深度学习与强化学习逐渐积累起可观的人气,2017年技术业界为我们带来越来越多在线录制与发布的讲座、训练营以及会议活动。以下是我个人最喜欢的部分重要资源:
- Deep RL Bootcamp 由OpenAI与加州大学伯克利分校联合主办,其中包含强化学习基础知识与相关最新研究成果。
https://sites.google.com/view/deep-rl-bootcamp/lectures?authuser=0
http://cs231n.stanford.edu
- 课程视频
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://web.stanford.edu/class/cs224n
- 课程视频
https://www.youtube.com/playlist?list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6
https://stats385.github.io
https://www.coursera.org/specializations/deep-learning
http://videolectures.net/deeplearning2017_montreal
http://rll.berkeley.edu/deeprlcourse
- TensorFlow开发者峰会,其中主要探讨深度学习基础知识以及相关TensorFlow API。
https://www.youtube.com/playlist?list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
也有不少重要的学术会议继续保持着仅进行在线发布的传统。如果大家希望紧随尖端研究成果,则可关注下述顶级会议的相关录音资料。
- NIPS 2017
https://nips.cc/Conferences/2017/Videos
- ICLR 2017
https://www.facebook.com/pg/iclr.cc/videos
- EMNLP 2017
https://ku.cloud.panopto.eu/Panopto/Pages/Sessions/List.aspx
研究人员们也开始在ArXiv上发布可轻松获取的教程与调查性论文。以下为今年我个人最为推荐的内容:
- 深度强化学习:概论
https://arxiv.org/abs/1701.07274
- 面向工程师的机器学习简介
https://arxiv.org/abs/1709.02840
- 神经机器翻译
https://arxiv.org/abs/1709.07809
https://arxiv.org/abs/1703.01619
- 实际应用:人工智能与医学 -
2017年内,我们还看到一系列关于深度学习技术顺利解决医疗问题,同时力压人类专家的大胆声明。不过其中仍存在不少炒作,而且不具备医学背景的人士也很难了解其中真正的突破性成效。要对这类趋势进行全面的了解,我推荐由Luke Oakden-Rayner撰写的“人类医生的末日”系列博文:
https://lukeoakdenrayner.wordpress.com/2017/04/20/the-end-of-human-doctors-introduction
接下来,我将向大家简要介绍这一领域中的部分发展成果。
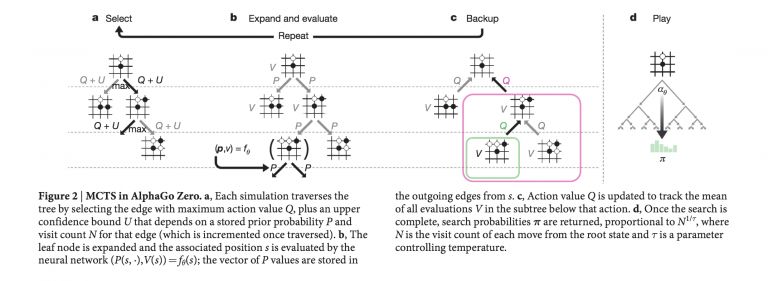
作为今年一项重磅新闻,斯坦福大学的一支研究团队发布了一项深度学习算法的细节信息,其能够有效帮助皮肤科医生诊断皮肤癌。
- 相关研究
https://cs.stanford.edu/people/esteva/nature
- 论文
https://www.nature.com/articles/nature21056.epdf?author_access_token=8oxIcYWf5UNrNpHsUHd2StRgN0jAjWel9jnR3ZoTv0NXpMHRAJy8Qn10ys2O4tuPakXos4UhQAFZ750CsBNMMsISFHIKinKDMKjShCpHIlYPYUHhNzkn6pSnOCt0Ftf6
斯坦福大学的另一个研究小组则开发出一套模型,能够帮助心脏病专家更好地通过单导联心电图信号诊断心律失常症状。
- 相关研究
https://stanfordmlgroup.github.io/projects/ecg
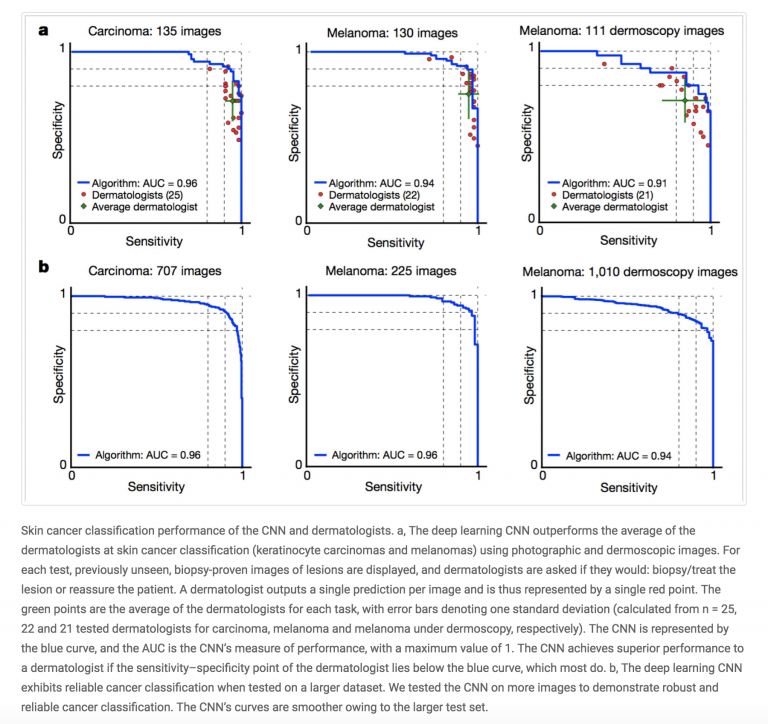
不过,过去一年当中,失误也仍然存在。DeepMind对英国国民健康保险制度(简称NHS)数据分析犯下了“不可原谅”的错误,而美国国立卫生研究院向科学界发布的胸部X射线数据集亦最终被证明并不适合用于训练诊断型AI模型。
- 应用方向:艺术与GAN -
今年当中,另一大引发广泛关注的应用方向在于图像、音乐、蓝图以及视频的创成式建模。NIPS 2017大会今年亦首次推出了“创新与设计型机器学习”工作室:https://nips2017creativity.github.io
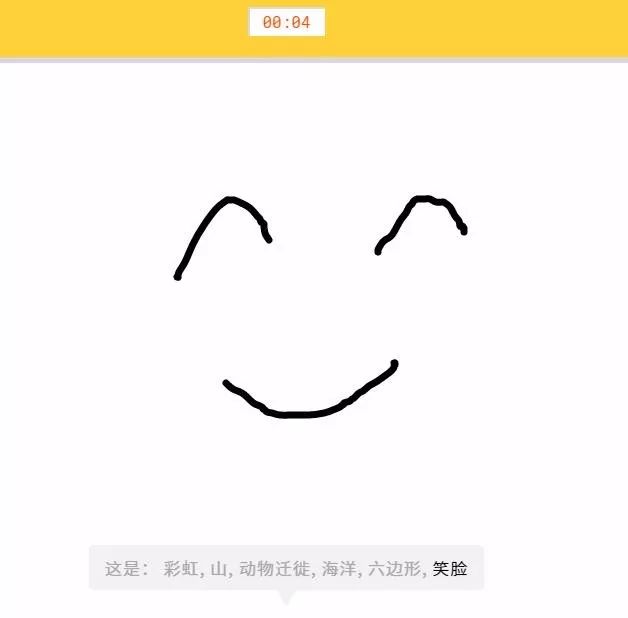
此类方案当中,最为流行的成果之一当数谷歌公司的QuickDraw,其利用神经网络对我们的涂鸦内容加以识别。利用已经发布的数据集,大家甚至能够教会机器将自己的绘图补充完全。
- QuickDraw快速涂鸦
https://quickdraw.withgoogle.com
创成式对抗网络(简称GAN)亦在今年取得了重大进展。以CycleGAN、DiscoGAN以及StarGAN为代表的各类新型模型在人脸生成方面取得了令人印象深刻的成就。从传统角度讲,GAN一直难以生成逼真的高分辨率图像,但如今 pix2pixHD 的成果展示让人眼前一亮,亦证明我们已经开始攻克这一难题。GAN未来会成为艺术家们新的画笔吗?
- CycleGAN
https://arxiv.org/abs/1703.10593
- DiscoGAN
https://github.com/carpedm20/DiscoGAN-pytorch
- StarGAN
https://github.com/yunjey/StarGAN
- 应用方向:自动驾驶汽车 -
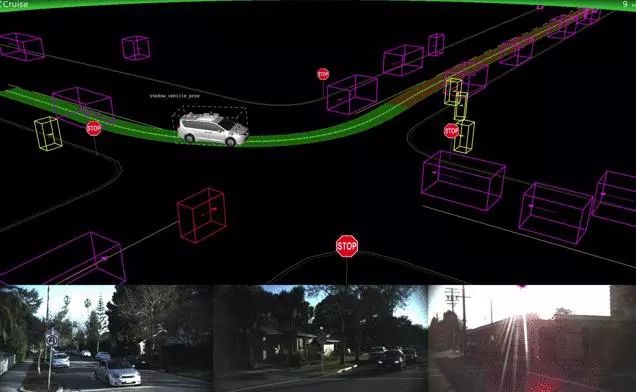
自动驾驶领域的巨头分别为Uber、Lyft、Alphabet下辖的Waymo以及特斯拉。Uber的方案由于软件错误而在旧金山的试验性驾驶当中闯了几次红灯,但并不像之前媒体报道的那样出现过人为失误。在此之后,Uber共享了其内部使用的汽车可视化平台细节信息。Uber的自动驾驶车辆项目到去年12月已经累计行驶了200万英里。
https://eng.uber.com/atg-dataviz
与此同时,Waymo的自动驾驶车辆在去年4月正式开始服役,并在随后的亚利桑那州凤凰城车赛中击败人类选手。Waymo方面同样公布了其测试与模拟技术的细节信息。
Lyft宣布其正在着手构建自己的自动驾驶硬件与软件方案。其部署于波士顿的首套试验性方案目前正在推进当中。特斯拉的Autpilot还没有作出太多更新。 另外,苹果公司也已经加入这一领域,Tim Cook证实称苹果方面正在开发用于自动驾驶车辆的软件,且研究人员已经在ArXiv上发布了一篇与测绘相关的论文。
https://arxiv.org/abs/1711.06396
- 应用方向:酷炫研究项目 -
过去一年中,出现了大量有趣的项目与演示成果,我们不可能在这篇短短的文章中将其全部囊括。不过下面是我汇总自过去一年的各大焦点项目:
- 利用深度学习实现背景消除
https://towardsdatascience.com/background-removal-with-deep-learning-c4f2104b3157
- 利用深度学习创造动漫角色
http://make.girls.moe/#/
https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/
- 神经网络玩《马里奥赛车》(超任版)
https://www.polygon.com/2017/11/5/16610012/mario-kart-mariflow-neural-network-video
- 面向《马里奥赛车64》的实时AI
https://github.com/rameshvarun/NeuralKart
- 利用深度学习发现伪造品
https://www.technologyreview.com/s/609524/this-ai-can-spot-art-forgeries-by-looking-at-one-brushstroke/
https://affinelayer.com/pixsrv/index.html
以下为其它研究方向:
- 无监督情感神经元 - 这是一种在学习情感方面拥有极佳表现的系统,不过其训练目的仅仅是为了预测Amazon评论文本中可能出现的下一个字符。
https://blog.openai.com/unsupervised-sentiment-neuron/
- 学习交流 - 各代理将开发出自己的语言。
https://blog.openai.com/learning-to-communicate
https://arxiv.org/abs/1712.01208
https://arxiv.org/abs/1706.03762
- Mask R-CNN – 一套面向对象实例拆分的通用型框架
https://arxiv.org/abs/1703.06870
- Deep Image Prior:去噪、超分辨率与修复
https://dmitryulyanov.github.io/deep_image_prior
- 数据集 -
用于监督学习的神经网络一直以对数据素材的迫切需求而闻名。正因为如此,开放数据集的出现对研究界而言亦成为一项非常重要的贡献。以下是今年出现的几套关键性数据集:
- Youtube Bounding Boxes
https://research.google.com/youtube-bb/
- 谷歌QuickDraw Data
https://quickdraw.withgoogle.com/data
https://deepmind.com/research/open-source/open-source-datasets
- 谷歌语音命令数据集
https://research.googleblog.com/2017/08/launching-speech-commands-dataset.html
- Atomic Visual Actions
https://research.google.com/ava/
- Open Images数据集的多项更新
https://github.com/openimages/dataset
- Nsynth音符注释数据集
https://magenta.tensorflow.org/datasets/nsynth
- Quora Question Pairs
https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
- 深度学习、重现性与炼金术 -
过去一年来,一部分研究人员对于学术论文结果的可重现性提出了担忧。深度学习模型通常需要大量超参数的介入,必须对其进行优化才能获得理想的结果。但这种优化工作可能需要大量成本,意味着只有谷歌以及Facebook这类巨头级企业才有能力负担。研究人员们有时并不会发布其代码,选择不在论文当中体现重要的细节,使用略有不同的评估程序,或者通过在同一分组之上重复优化超参数来过度使用数据集等等。这一切使得重现性成为一大难题。研究人员们指出,在强化学习领域,利用不同代码库采取相同算法将得出完全不同的结果与高方差:
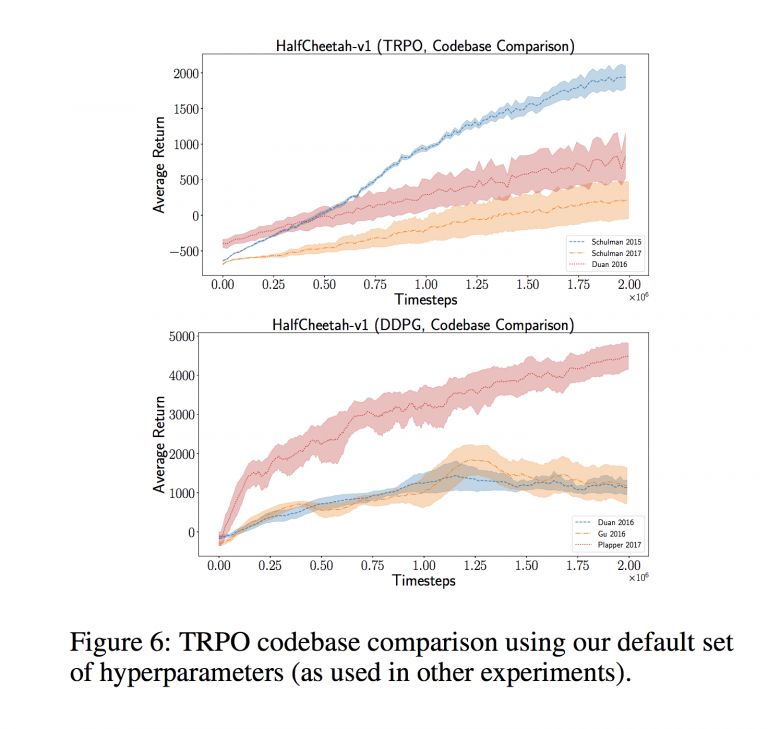
在《GAN是否会得出对等的结果?一项大规模研究》当中,研究人员们发现利用成本极高的超参数搜索进行调整的GAN往往具有更出色的成效,并以此种结果作为其优越性的证明。同样的,在《神经语言模型的评估现状》一文中,研究人员们表明只要经过适当的规范化与调整,简单的LSTM架构也能够获得超越其它更新模型的效能。
- 两篇论文地址
https://arxiv.org/abs/1711.10337
https://arxiv.org/abs/1707.05589
在有多位研究人员共同参与的一次NIPS讨论当中,Ali Rahimi将近期的深度学习方法与中世纪的炼金术进行了比较,并呼吁应采取更为严格的实验设计。Yann LeCun则将这样的说法视为侮辱甚至是挑衅,并于第二天作出了回应。
https://www.youtube.com/watch?v=Qi1Yry33TQE
- 人工智能:加拿大与中国制造 -
随着美国移民政策的收紧,越来越多的企业开始在海外开设办事处,而加拿大则成为首选目的地。谷歌在多伦多开设了新的办公室,DeepMind在加拿大埃德蒙顿建立新的办公室,Facebook AI Research也将业务扩展至蒙特利尔。
中国则是另一个广受关注的目的地。由于拥有大量资金、可观的人才储备以及现成的政府数据,中国正在立足人工智能开发与生产部署同美国开展直接竞争。谷歌公司还宣布即将在北京开设新的实验室。
硬件之争:英伟达、英特尔、谷歌与特斯拉
现代深度学习技术的一大特色,在于其要求利用昂贵的GPU资源对最先进的模型加以训练。到目前为止,英伟达公司一直是这一领域中的大赢家。今年,该公司公布了最新TITAN V旗舰级GPU。然而,竞争热度正在持续升级。谷歌公司的TPU目前已经开始通过其云平台交付,英特尔旗下的Nervana推出一款新型芯片,甚至特斯拉公司都表示其正在开发自己的AI硬件。当然,中国也可能贡献更多竞争势力——专门从事比特币采矿的硬件制造商们也希望迈入以人工智能为核心的GPU业务领域。
- 炒作与失败 -
目前的炒作态势仍然非常夸张。主流媒体的报道与研究实验室或者生产系统中的实际结果几乎毫无关系。IBM沃森即是过度营销层面的传奇之作——其根本无法带来与名声相符的能力。2017年,每个人都对IBM沃森感到失望——考虑到其在医疗方面的一再失败,这样的结论并不令人意外。
而另一大炒作故事当数Facebook中“研究人员们关闭了一套自行发明语言的AI”,好奇的朋友可以自行搜索相关内容。总而言之,这就是彻头彻尾的标题党,真实情况是研究人员们因为实验结果不好而关闭了一项测试。
当然,这一切也不能全怪新闻媒体。研究人员本身也存在过度描述的问题,包括在某些论文当中作出与实际实验结果不符的说明。
- 加盟与离职 -
Coursera联合创始人吴恩达于2017年3月离开了百度并创立自己的AI公司,随后他筹集到1.5亿美元资金并建立起新初创企业landing.ai,专注于制造业。此外,Gary Marcus辞去了Uber人工智能实验室主任的职务,Facebook吸纳Siri自然语言理解负责人,另有几位著名研究人员离开OpenAI开创自己的机器人公司。
学术界的科学家们也在纷纷“下海”,各大高校实验室纷纷抱怨称他们无法在薪酬层面同各行业巨头进行竞争。
- 初创企业投资与收购 -
与上一年一样,217年的AI初创企业生态系统仍在蓬勃发展,并完成了多项重要收购:
- 微软收购深度学习初创企业Maluuba公司
- 谷歌云收购Kaggle公司
- 软银收购机器人制造商Boston Dynamics公司(但该机器人厂商很少使用机器学习技术)
- Facebook 收购AI助手初创企业Ozlo公司
- 三星收购 Fluently以巩固Bixby技术实力
此外还有几家刚刚筹得可观资金的新公司:
- Mythic筹得880万美元以研发芯片上AI技术
- Element AI平台可供企业客户构建AI解决方案,融资1.02亿美元
- Drive.ai融资5000万美元,并喜迎吴恩达加入董事会
- Graphcore筹得3000万美元
- Appier在C轮融资中筹得3300万美元
- Prowler.io融资1300万美元
- Sophia Genetics 筹得3000万美元,旨在帮助医生利用AI与基因数据实现诊断
新年快乐!感谢您的耐心阅读:)


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

数智风起辽沈:从矿山到低空,看老工业基地的智能新生
这里曾是中国重工业的摇篮,装备制造业的轰鸣声响彻几代人。如今,这片土地不再只依赖钢筋铁骨,而是主动拥抱数智化的浪潮,用算力和算法书写东北振兴的新篇章。

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路
陈立武的到来,像一颗石子投入平静湖面,激起涟漪的同时,也让人好奇:这位65岁的“半导体老兵”能做到什么程度?
 2025-03-20 10:11
2025-03-20 10:11黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员
在GTC2025大会上,英伟达CEO黄仁勋在一场至顶科技等全球媒体共同参与的记者会上表示, AI正在成为一个全新的制造业。AI不是传统意义上的软件开发,而是一场需要基础设施、能源和资本投入的产业革命。


数智风起辽沈:从矿山到低空,看老工业基地的智能新生

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路

黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员

AMD如何推动AI PC普及?
