 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
解析机器学习应用:数据中心和云计算成为企业新战场
机器学习作为一种实现人工智能的方法,近年来成功案例数日益攀升,已经从一个相对模糊的计算机科学概念,迅速发展成为企业经济的影响因素,因此,机器学习领域存在大量的资金投入也就一点儿也不让人感到奇怪了。
麦肯锡公司的一项调查显示,在2013年至2016年期间,人工智能开发投资总额增加了两倍,其中大部分投资——200亿至300亿美元——都来自一些科技巨头,这些公司希望能够产生机器学习以及其他人工智能模型,而这些技术在未来对于他们的客户来说,会变成像今天的移动和网络一样至关紧要的东西。
人工智能技术之所以能够如此吸引人,是因为存在巨大的商业价值。Gartner预测到2020年,人工智能技术在新的商业软件中会变得无处不在,而且将成为30%的首席信息官投资优先级中排名前五的技术之一。
事实就目前看来,人工智能市场中大部分的推动力都来自于那些树大根深的公司:
- 英伟达已经成为GPU中的主导者,成为机器学习培训阶段的首选平台。到目前为止,这是机器学习绝大部分的焦点所在。
- 英特尔推出了Nervana神经处理器(Nervana Neural Processor),这是一款低延迟、高内存带宽芯片,据说这款处理器是专门为了深度学习设计的。(英特尔于2016年收购了Nervana)。
- 谷歌的张量处理单元(Tensor Processing Unit,TPU)已经在机器学习加速器市场上站稳了脚跟,现在已经发展到第二版本。第一个版本是谷歌开发的一款专用集成电路(ASIC),目标是为了在其自己的服务器上加速其语音转换文本应用程序的推理;和第一个版本相比,第二个版本——云TPU(Cloud TPU)——更像是一个高性能的TPU集群,旨在作为训练模块与英伟达(Nvidia)竞争。
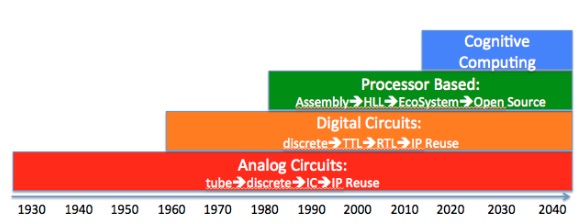
简单而言,机器学习直接来源于早期的人工智能领域,传统算法包括决策树学习、推导逻辑规划、聚类、强化学习和贝叶斯网络等等。
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习基于大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
本文主要针对数据中心和云计算,而这本身就是一个巨大的市场,也是机器学习的根基。Linley集团的首席分析师Linley Gwennap预测,以数据中心为导向的人工智能加速器市场到2022年将达到120亿美元的规模:“在接下来的一到两年里,我们将开始看到更多数据中心和其他设备的选择。”他认为,“目前,类似谷歌和Facebook这样的科技巨头面临的问题是,‘我该坚持设计自己的芯片吗?或者,如果企业能够在开放市场得到同样的经济效益,我需要尝试吗?’”
机器学习下一阶段
很多公司会交替使用机器学习、深度学习、人工智能和神经网络等技术,尽管这些技术彼此之间存在着微妙的差别,但总的来说,都是基于实时数据,计算机可以权衡很多不同的情况,并根据这些预设的权重做出最好的选择——也就是数据挖掘。加权的过程是“训练”阶段的一部分,而“推理”阶段是机器学习的核心。
数据挖掘是个很宽泛的概念,数据挖掘常用方法大多来自于机器学习,深度学习是机器学习一类比较火的算法——具有更多层次不同类型的分析,并最终形成更完善的解决方案,而这样做的代价是需要消耗更多的计算资源才能完成“训练”阶段。两者本质还是涉及神经网络,它们围绕信息节点创建类似网状的连接,这与人类大脑中的神经元与周围的细胞进行网状连接的方式非常相似。人工智能是一个总括性的术语,对许多不同的人来说意味着许多不同的东西,从IBM的Watson到电影《2001:太空漫游》的HAL。但总来说,它指的是设备可以独立于显式编程学习行为。
机器学习的第二阶段就是“推理”,这个阶段基本上就是要把学习阶段的成果应用到特定的应用程序和细分市场,也就是算法被投入实际应用的地方,机遇更大。结果或许是大量获得风投支持的初创公司蜂拥而至。
ARM公司员工Jem Davies表示,“机器学习的推理和训练阶段完全是两码事。”
所谓推理,你可以做各种古怪的事情,如分拣黄瓜等。它更接近用户,这就是为什么你看到各种有趣的案例。但现在的手机也有预测性文本,和推理类似——这是25年前开始的。”推理是辅助自动驾驶的重要组成部分,从传感器收集上来的数据也需要基于机器学习进行预处理。
Cadence公司Tensilica DSP部门的产品营销总监Pulin Desai表示:“推理需要在边缘进行。”他举例,“在一辆汽车里,你可能有20个图像传感器,加上雷达和激光雷达,以提供360度的视野。但是如果你把一个图像传感器放在汽车上,它可能有180度的视野。这需要畸变校正,这是图像处理。”
训练和推理阶段之间的一个关键区别在于,训练是在浮点中完成的,而推理则是使用定点。DSP和FPGA是定点。
这里简单说一下ARM、DSP和FPGA,市场经常拿来对比。
在嵌入式开发领域,ARM(Advanced RISC Machines)是一款微处理器,设计了大量RISC处理器、相关技术及软件,提供一系列内核、体系扩展、微处理器和系统芯片方案,目前市场覆盖率90%以上;DSP(digital singnal processor)是一种独特的微处理器,有自己的完整指令系统,是以数字信号来处理大量信息的器件:一个数字信号处理器在一块不大的芯片内包括有控制单元、运算单元、各种寄存器以及一定数量的存储单元等等,在其外围还可以连接若干存储器,并可以与一定数量的外部设备互相通信,有软、硬件的全面功能,本身就是一个微型计算机;FPGA(Field Programmable Gate Array,现场可编程门阵列)是在PAL、GAL、PLD等可编程器件的基础上进一步发展的产物,是专用集成电路(ASIC)中集成度最高的一种。
三者区别在于,ARM具有比较强的事务管理功能,可以用来跑界面以及应用程序等,其优势主要体现在控制方面;而DSP主要是用来计算的,比如进行加密解密、调制解调等,优势是强大的数据处理能力和较高的运行速度;FPGA可以用VHDL或verilogHDL来编程,灵活性强,由于能够进行编程、除错、再编程和重复操作,因此可以充分地进行设计开发和验证。当电路有少量改动时,更能显示出FPGA的优势,其现场编程能力可以延长产品在市场上的寿命,而这种能力可以用来进行系统升级或除错。
Flex Logix公司首席执行官Geoffrey Tate表示:“我们正在摆脱使用x86处理器解决所有问题或者人们需要为特定工作负载优化硬件的局面。大多数计算将在数据中心之外完成,因此FPGA和其他一些东西的角色将不得不发生改变——由于支持音视频的需求的扩展,你可能仍然会看到传统架构和新架构混合。我认为我们都是加速器。”
机器学习领域,FPGA和eFPGA玩家正在争先恐后地进入推理市场。预计2022年将有17亿个机器学习客户端设备。
Achronix公司总裁及首席执行官Robert Blake表示:“在机器学习的学习阶段,GPU已经赢得了很多关注。” 他表示,“但是更大的市场将会在推理方面,这些产品的成本和功耗将是至关重要的。这就是为什么在这些领域内嵌入式解决方案将具有极大吸引力的原因。”
ARM公司员工Davies也同意这种看法。他说,功率预算保持在2-3瓦的范围内,而电池技术的改进则相对“不给力”。锂电池的改进一般在每年4%-6%的范围内。相比而言,为了完成所有这些工作所需的计算性能的提升则是数量级的提升。
这将需要一个完全不同的架构,包括对于在哪里完成哪种处理的理解。
Rambus公司一位发明家Steven Woo表示:“我们看到了人工智能、神经网络芯片和内核的市场需求,更高级别的需求是它们把信息融合在一起,而现在市场正在摸索人工智能、神经网络芯片和内核‘融合’的可能。你现在看到的是,很多公司在寻找主要的市场,并围绕这些市场建设基础设施。譬如汽车市场;还有手机市场,那里有几十亿设备的规模,它们正在推动新的打包基础设施;而且物联网也有潜力,但挑战在于找到共性。而神经网络和机器学习,似乎每周都有新的算法,这就很难开发一个单一的架构。这就是为什么你看到人们对FPGA和DSP的兴趣之深的原因。”
机器学习的行业应用
机器学习在以客户为中心的应用程序中已经变得相当常见,它可以被用来预测销售情况,寻找客户流失的迹象,通过交互式语音响应或者通过在线聊天机器人,以及谷歌翻译之类的消费者应用程序提供客户服务。
Facebook使用三个深度学习应用程序来过滤上传内容,例如,一个在上传图片中进行面部识别并对人进行标记,一个检查仇恨言论或者其他目标内容,而另一个用于定位广告。
西门子旗下Mentor公司传感器融合首席工程师Nizar Sallem表示,深度学习在客户服务和分析方面可能很适合,但它也是提供自动驾驶车辆所需的即时感知、决策和控制系统的首选对象。机器学习了解车辆周围的环境,道路上的不同行为者,交通规则以及当时期望车辆所处的位置,它必须确定你的行为应该是什么样子的,还要确定什么时候你可以为了逃避危险或者保护车内的人而违反交通规则。
英伟达首席科学家兼研究高级副总裁Bill Dally表示, “让我吃惊的是深度学习革命来的如此之快。在过去的三年中,各种各样的应用程序似乎一夜之间就放弃了原来的传统方法,摇身一变转向了深度学习。”他补充说,“这不需要在软件上投入巨大的资金;你拿一个应用程序,训练网络,然后就完成了。它在某些领域已经变得无处不在,但是对于每个摇身一变拥抱了神经网络的应用程序来说,都还有另外十次‘摇身一变’的机会。”
麦肯锡认为,在科技行业以外人工智能大部分的应用都是试验性的,而在科技行业中,大部分人工智能的应用要么是为了支持或改善其他服务,要么就是为消费者增加新的服务。在接受麦肯锡调查的3000多家公司中,只有20%的企业表示他们在重要的业务部分使用了与人工智能相关的技术。调查发现了160个人工智能的使用案例,麦肯锡发现只有12%的商业应用。
或者换个角度看,88%的公司还没有在商业上部署人工智能,这是一个巨大的机会。相比之下,包括谷歌和百度在内的高科技公司在2016年花费了200亿至300亿美元,其中90%用于研发,10%用于收购。
市场预测
尽管人工智能技术处于爆发期,但发展仍处于起步阶段。主流提供商仍然是现有的高科技公司,而最能赚钱的仍然是消费者服务。Tractica报告称,这包括谷歌的语音到文本转换和翻译服务以及来自亚马逊、Facebook、百度等公司的消费者互动/客户服务应用程序。该报告估计,2016年人工智能驱动的消费服务价值为19亿美元,到2017年底将增至27亿美元。
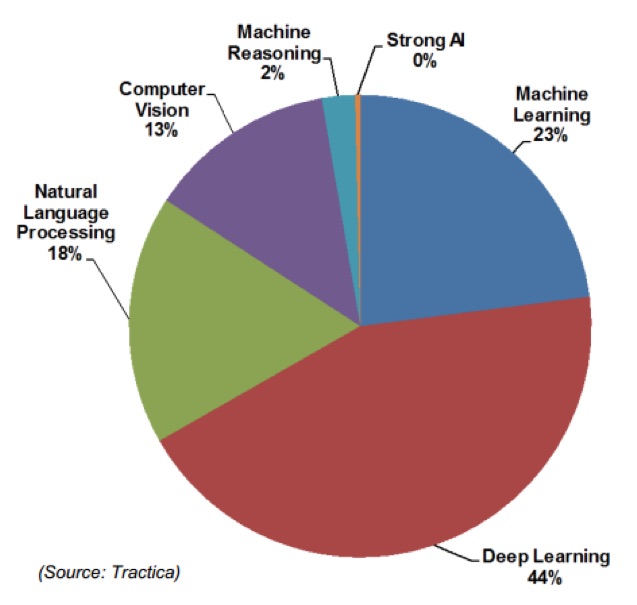
图:按技术划分的人工智能收入。资料来源:Tractica
Tractica估计到2025年,包括硬件、软件和服务在内的整个人工智能市场将上升到421亿美元。
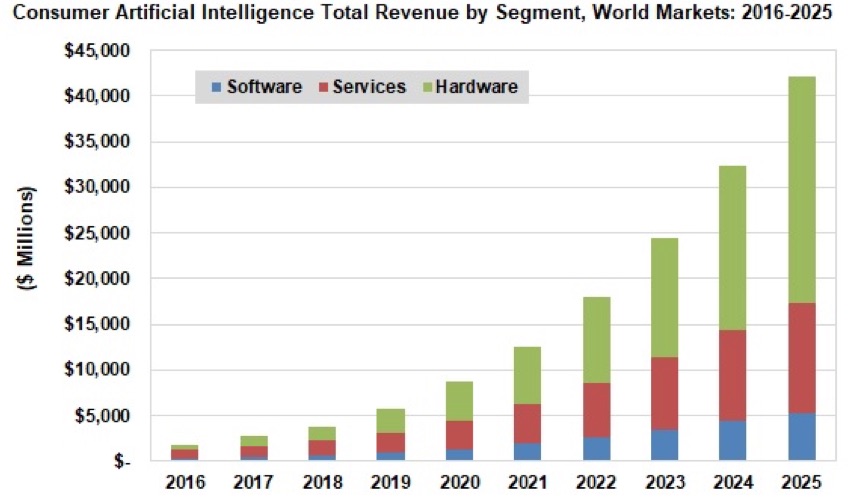
图:人工智能各部分的收入。资料来源:Tractica
机器学习即服务(MLaaS)是另一个类别,其中73%由亚马逊、IBM和微软占据。Transparency Market Research(TMR)4月份的一份报告表示,预计这一数字将从2016年的约10.7亿美元增长到2025年的199亿美元。
Tractica表示,大部分机器学习功能服务目前针对的都是消费者——这个类别中包含了谷歌翻译和语音转换文本应用程序,作为其客户TPU的概念验证。深度学习成为半导体行业新战场
深度学习的出现也凸显了半导体行业与其最大客户之间的一些日益复杂的关系,特别是同谷歌和其他超大规模数据中心所有者之间的关系,他们的规模大到足以配置并建设自己的服务器和芯片。
芯片公司多年来一直在针对特定云客户的需求构建或定制芯片。例如,英特尔就为微软打造了FPGA DL加速器,为阿里巴巴云客户打造了基于FPGA的应用加速器。英特尔还邀请Facebook帮助设计英特尔Nervana神经处理器(Nervana Neural Processor)的包装以及该公司即将推出的、针对深度学习的“Lake Crest”专用集成电路(ASIC)。
谷歌已经发布了其他芯片,包括它已经开发了Pixel2手机的机器学习协处理器的消息,这是它的首款移动芯片。谷歌还开发了Titan,这是一种微控制器,连接到服务器上,以确保它们不会错误启动、损坏或被恶意软件感染。
谷歌称TPU可以实现“机器学习每瓦性能优化,优化的幅度是数量级的”并将谷歌的机器学习应用程序向前推进了七年,以此证明它对TPU的投资是合理的。首款TPU只针对加速运行机器学习模型推理的普通服务器设计,而不是首先瞄准了培训模型。因此,它们并没有直接同英伟达或者英特尔的机器学习培训产品竞争。
当谷歌在5月份发布其云TPU(Cloud TPUs)时,该公司的声明听起来像是要与英特尔和英伟达进行更为直接的竞争。
谷歌宣称Cloud TPU每个浮点性能为180 teraflops,但将这些单元打包成4-TPU Pod,总共包含11.5 petaflops。这种配置似乎是为了与英伟达备受好评的DGX-1“超级计算机”竞争,该超级计算机配备了八个顶级的Tesla V100芯片,并声称总计最高吞吐量为1petaFLOP。
来自云端的竞争
Dally 表示,“谷歌和其他一些公司已经在没有加速——或者只有TPU——的情况下获得了早期的成功,但是有一些网络很容易培训;标准图像搜索很简单。”他表示,“但是如果要进行更多信号处理的培训——处理图像和视频流,以及对于那些每周都要重新培训他们的网络的人来说,或者对于那些更加重视培训的人来说,GPU的效率要高得多。”
Chris Rowen是Cadence 的IP集团的前首席技术官,他创办了Cognite Ventures,为神经网络、物联网和自动驾驶嵌入式系统的创业企业提供资金和建议。他表示,问题是谷歌的新处理器是否足以将客户从其他业务中剥离出来,答案可能会是“不能”。任何一家云提供商都必须支持多种架构,所以支持深度学习的数据中心将会成为CPU、GPU、ASIC、FPGA以及来自各种技术的IP的盛宴。
Rowen表示,一些培训负载也有可能更多地转移到内置在客户端设备中的推理引擎上。在这个领域的很多公司肯定会有机会。不过,对于限制在数据中心服务器上的机器学习培训,就很难取代现有的玩家了。
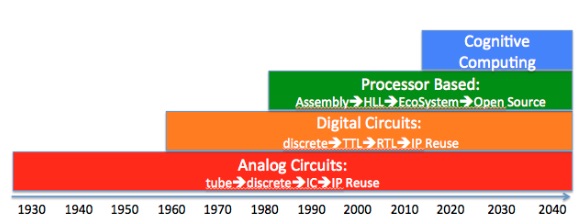
图:认知计算的演变。资料来源:Cognite Ventures
<来源:semiengineering.com;作者:Kevin Fogarty;编译:科技行者>


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

奇客情报站

奇客故事

数智风起辽沈:从矿山到低空,看老工业基地的智能新生
这里曾是中国重工业的摇篮,装备制造业的轰鸣声响彻几代人。如今,这片土地不再只依赖钢筋铁骨,而是主动拥抱数智化的浪潮,用算力和算法书写东北振兴的新篇章。

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路
陈立武的到来,像一颗石子投入平静湖面,激起涟漪的同时,也让人好奇:这位65岁的“半导体老兵”能做到什么程度?
 2025-03-20 10:11
2025-03-20 10:11黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员
在GTC2025大会上,英伟达CEO黄仁勋在一场至顶科技等全球媒体共同参与的记者会上表示, AI正在成为一个全新的制造业。AI不是传统意义上的软件开发,而是一场需要基础设施、能源和资本投入的产业革命。


数智风起辽沈:从矿山到低空,看老工业基地的智能新生

陈立武的英特尔逆行记:从工程师文化到AI驱动的突围路

黄仁勋全球记者会:英伟达正在转型为一家AI基础设施公司,中国为AI产业贡献了50%的研究员

AMD如何推动AI PC普及?
